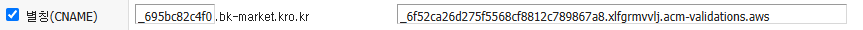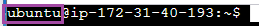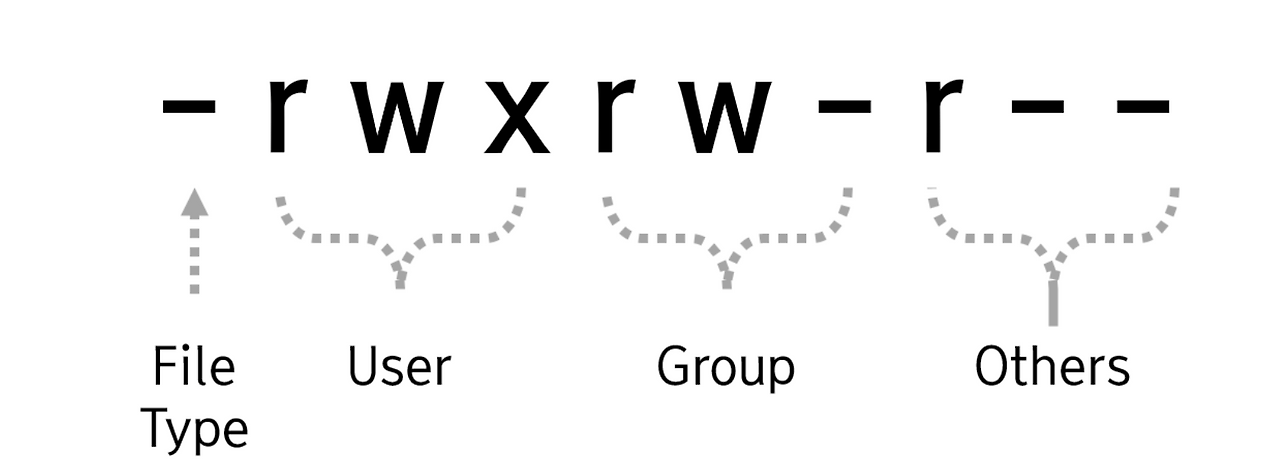이 강의 스타일은 " 1000점 만점 중에 1000점을 맞을 수 있는 강의가 아니라 합격 점수인 720점을 넘겨서 합격을 하는 데 초점이 맞춰진 강의" 이다. 짧은 시간에 핵심 개념들 위주로 학습하고 빈출 문제들로 학습하는 강의인데 5시간 정도로 강의 시간도 길지 않다.
확실히 자격증을 준비하는 강의로는 이렇게 컴팩트하게 짜여진 강의가 좋은것 같다.
나는 이 강의에서 제공하는 개념 및 163문제를 4회독 하고 덤프문제는 50문제정도 풀고 시험을 보러갔다.
덤프문제를 더 많이 풀지 않은것은 많은 문제를 풀기만 하고 정리되지 않은 채로 시험을 보는것보다는 여러번 풀어보면서 문제에서 출제되는 기능의 개념이나 사용방식을 제대로 이해해야 처음 보는 문제도 풀 수 있을거라는 생각이었다.
공부하면서 느낀것은 반복해서 문제를 풀다보면 처음 문제를 풀때는 안 보이던 포인트 들이 보이기 시작하고 같은 문제를 풀더라도 풀때마다 이해도가 좀 더 오르는 느낌이었다.
시험 후기
문제를 풀면서 사실 많이 당황스러웠다. 생각보다 문제가 어렵게 느껴졌고 모르는 기능도 많이 나와서 다음 시험을 준비해야 할 수도 있겠다고 생각했다. 그래도 최대한 집중해서 한문제씩 풀어 나갔고 20분 정도 남기고 마무리했다.
헷갈리는 문제는 Flag 기능을 활용해서 나중에 검토할 수도 있는데 나는 한 문제도 다시보지는 않았다.
다시봐도 정답이 보일 것 같지도 않고 150분 동안 집중력을 쏟아내서 다시 문제를 볼 힘도 없었다.
참고로 시험 신청 전에 영어로 시험을 보는 경우가 아닌 경우 30분 추가 시간을 받을 수 있으니 30분 추가를 먼저 신청하고
시험을 신청할 것을 추천한다.
결과
어쨋든 그날 오전 9시30분 즈음 시작해서 12시 조금 넘어서 끝났고 그날 밤 결과를 확인 하였다.
진짜 재시험 볼 각오하고 있었는데 합격이었다. 그것도 꽤 여유있게 합격해서 놀랐다. 너무너무 다행이다.
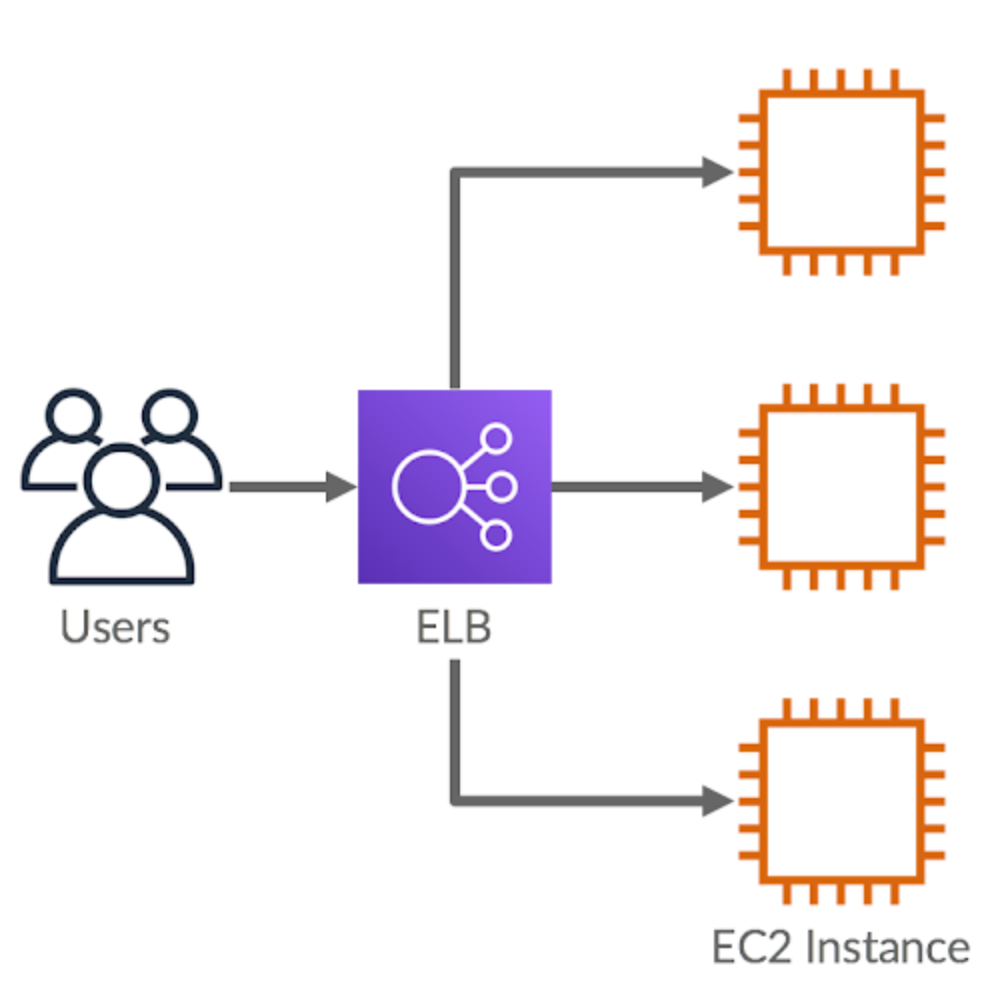
트래픽(부하)을 적절하게 분배해주는 장치를 로드맬런서(Load Balancer)라고 부른다.
서버를 2대 이상 가용할 때 ELB를 필수적으로 도입하게 된다.
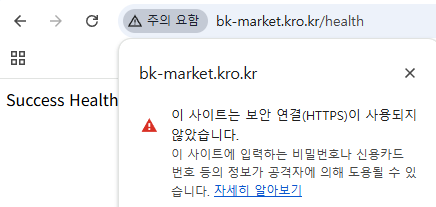
하지만 지금은 ELB의 로드밸런서 기능을 사용하지 않고, ELB의 부가 기능인 SSL/TLS (HTTPS) 를 적용시켜보려 한다.
SSL / TLS란?
SSL/TLS 를 쉽게 표현하자면 HTTP를 HTTPS 로 바꿔주는 인증서이다.
위에서 말했다시피 ELB는 SSL/TLS기능을 제공한다고 했다. SSL/TLS 인증서를 활용해 HTTP가 아닌 HTTPS로 통신할 수 있게 만들어준다.
HTTPS 란?
HTTPS 를 적용시켜야 하는 이유는 무엇일까?
1. 보안적인 이유
데이터를 서버와 주고 받을 때 암호화를 시켜서 통신한다. 암호화를 하지 않으면 누군가 중간에서 데이터를 가로채서 해킹할 가능성이 존재한다.
2. 인증
HTTPS 는 인증서를 통해 통신 상대(서버)의 신원을 보장한다. 즉, 사용자가 접속한 사이트가 "진짜"인지 "피싱 사이트"인지 구분할 수 있다.
3. 검색 엔진 우대
구글을 포함한 검색엔은 HTTPS 사이트를 우선적으로 노출한다.
4. 브라우저 경고 방지
최근(특히 Chrome, Edge 등)은 HTTPS가 아닌 사이트를 “안전하지 않음”으로 표시한다. 로그인 창이나 입력 폼이 있는 페이지에서 브라우저 경고창이 뜬다면 특히 신뢰를 잃을 수 있다.
ELB를 활용한 아키텍처 구성
ELB 도입 전 아키텍처
ELB 도입 전 아키텍처
ELB 를 사용하기 전의 아키텍처는 사용자들이 EC2 의 IP 주소 또는 도메인 주소에 직접 요청을 보내는 구조이다.
ELB 도입 후 아키텍처 : 서버 1대
ELB 도입 후 아키텍처 : 서버 2대
다수의 사용자가 한번에 몰리게되어 요청이 늘어나면 인스턴스를 추가하고 요청이 줄면 인스턴스를 다시 줄이는 기능이 있는데 이를 오토 스케일이라고 한다. ELB(Elastic Load Balancer)는 오토스케일링으로 늘어난 인스턴스에 요청을 트래픽(부하)을 분산하는 서비스이다.
ELB 세팅
기본 구성
1. 리전 선택
AWS EC2 -> 로드밸런서 서비스로 들어가서 리전(Region) 을 선택한다.
2. 로드 밸런서 유형 선택하기
로드 밸렁서 생성
로드 밸런서 유형 선택 : Application Load Balancer 선택
3. 기본 구성
인터넷 경계와 내부라는 옵션이 있다. 내부 옵션은 Private IP 를 활용할 때 사용한다. 당장 Private IP는 사용하지 않을 예정이기 때문에 인터넷 경계 옵션을 선택하면 된다.
IPv4 와 듀얼 스택 이라는 옵션이 있다. IPv6 를 사용하는 EC2 인스턴스가 없다면 IPv4 를 선택하면 된다.
4. 네트워크 매핑
로드 밸런서가 어떤 가용 영역으로만 트래픽을 보낼 건지 제한하는 기능이다. 가용 영역에 대한 개념은 제쳐두고 모든 영역에 트래픽을 보내게 설정하겠다.
보안그룹
1. AWS EC2 보안그룹 에서 보안 그룹 생성
보안 그룹 이름 지정
인바운드 규칙
ELB의 특성상 인바운드 규칙에 80(HTTP), 443(HTTPS) 포트로 모든 IP 에 대해 요청을 받도록 설정한다.
아웃바운드 규칙
2. ELB 만드는 창으로 돌아와서 보안 그룹 등록
리스너 및 라우팅 / 헬스 체크
1. 대상 그룹 (Target Group) 설정하기
리스너 및 라우팅 설정은 ELB로 들어온 요청을 어떤 EC2 인스턴스에 전달할 건지를 설정하는 부분이다.
ELB로 들어온 요청을 어딘가로 전달해야 하는데, 여기서 어딘가는 대상 그룹(Target Group)이라고 표현한다.
즉, ELB로 들어온 요청을 어디로 보낼 지 대상 그룹을 만들어야 한다.
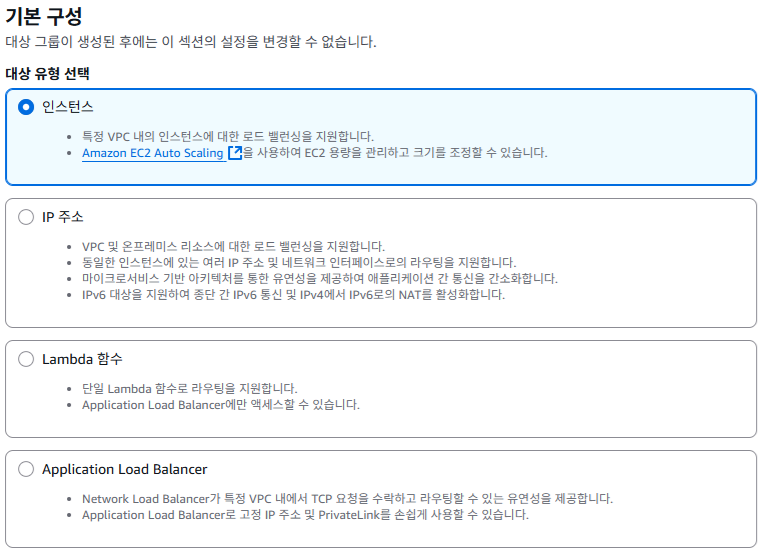
2. 대상 유형 선택하기
EC2 에서 만든 특정 인스턴스로 트래픽을 전달할 것이기 때문에 인스턴스 옵션을 선택
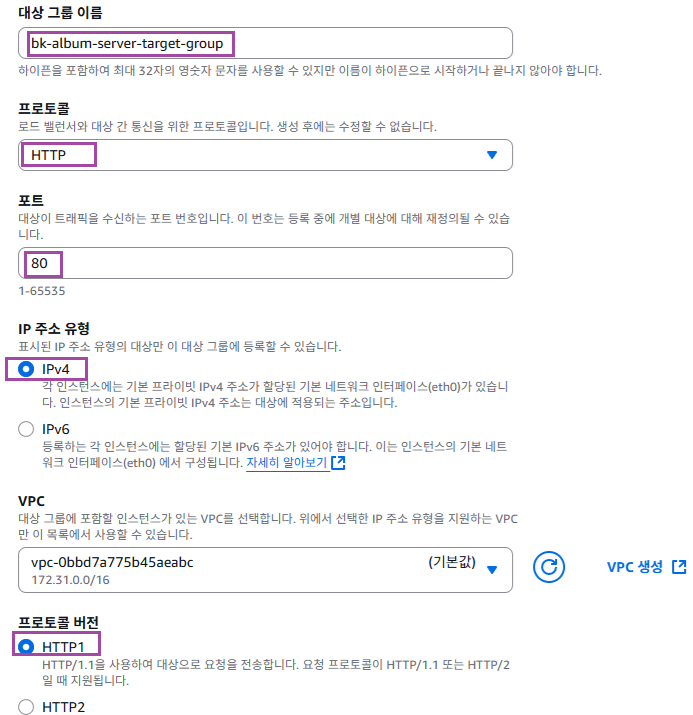
3. 프로토콜, IP 주소 유형, 프로토콜 버전 설정
ELB가 사용자로부터 트래픽을 받아 대상 그룹에게 어떤 방식으로 전달할 지 설정하는 부분이다.
HTTP1, 80번 포트, IPv4 주소로 통신하도록 설정
4. 상태 검사 설정하기
ELB의 부가 기능으로 상태검사 ( = Health Check, 헬스 체크 ) 기능이 있다. 이 기능은 굉장히 중요한 기능이므로 짚고 넘어갈 필요가 있다.
ELB는 들어온 요청을 대상 그룹에 있는 여러 EC2 인스턴스로 전달하는 역할을 가진다. 그런데 만약 특정 EC2 인스턴스 내에 있는 서버가 예상치 못한 에러로 고장이 났다고 가정해보자. 그러면 ELB 입장에서는 고장난 서버한테 요청(트래픽)을 전달하는 것은 비효율을 유발한다.
이런 상황을 방지하기 위해 ELB는 주기적으로(기본 30초 간격) 대상 그룹에 속해있는 각각의 EC2 인스턴스에 요청을 보내본다. 그 요청에 대한 200번대(HTTP Status Code) 응답이 온다면 서버가 정상적으로 동작하고 있다고 판단하고 만약 요청을 보냈는데 200번대의 응답이 오지 않는다면 서버가 고장났다고 판단하여 ELB가 해당 EC2인스턴스로는 요청(트래픽)을 보내지 않는다.
이러한 작동 과정을 통해 조금 더 효율적인 요청(트래픽)의 분배가 가능해진다.
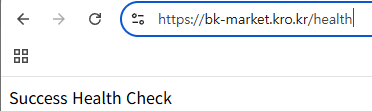
위에서는 대상 그룹의 각각의 EC2 인스턴스에 GET /health (HTTP 프로토콜 활용)으로 요청을 보내게끔 설정한 것이다.
정상적인 헬스 체크 기능을 위해 EC2 인스턴스에서 작동하고 있는 백엔드 서버에 Health Check용 API를 만들어야 한다.
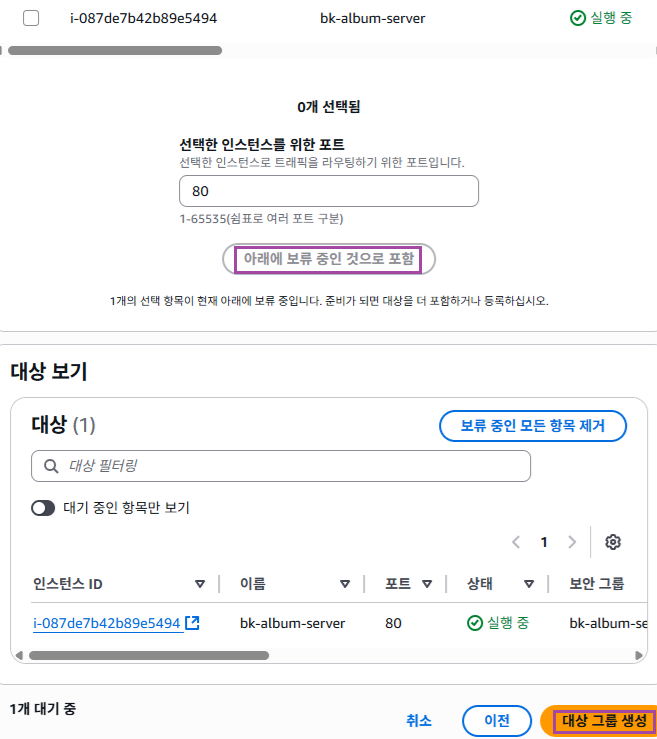
5. 대상 등록하기
6. ELB 만드는 창으로 돌아와 대상 그룹(Target Group) 등록하기
ELB 에 HTTP 를 활용해 80번 포트로 들어온 요청(트래픽)을 설정한 대상 그룹으로 전달하겠다는 의미
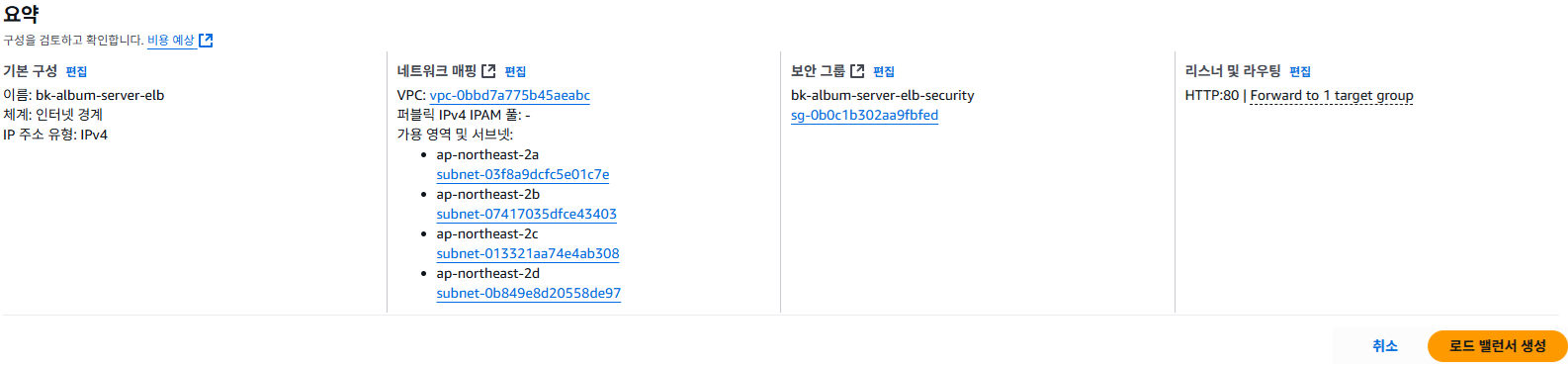
7. 로드 밸런서 생성하기
로드밸런서 주소를 통해 서버 접속
HealthCheckController 만들어놓기
Health Check 할 수 있는 컨트롤러를 간단히 만들어 놓았다.
@RestController
@Slf4j
public class HealthCheckController {
@GetMapping("/health")
public ResponseEntity<String> healthCheck() {
log.info("health check...");
return ResponseEntity.ok("Success Health Check");
}
}
application.properties 에서 서버 포트를 80으로 해놓아야 한다.
server.port=80
로드밸런서 주소를 통해 서버 접속
로드밸런서 주소를 통해 서버에 접속하여 헬스 체크가 정상동작함을 확인하였다.
Route53 에서 도메인 연결하기
1. 호스팅 영역 생성
Route 53 → 호스팅 영역에서 호스팅 영역을 생성한다.
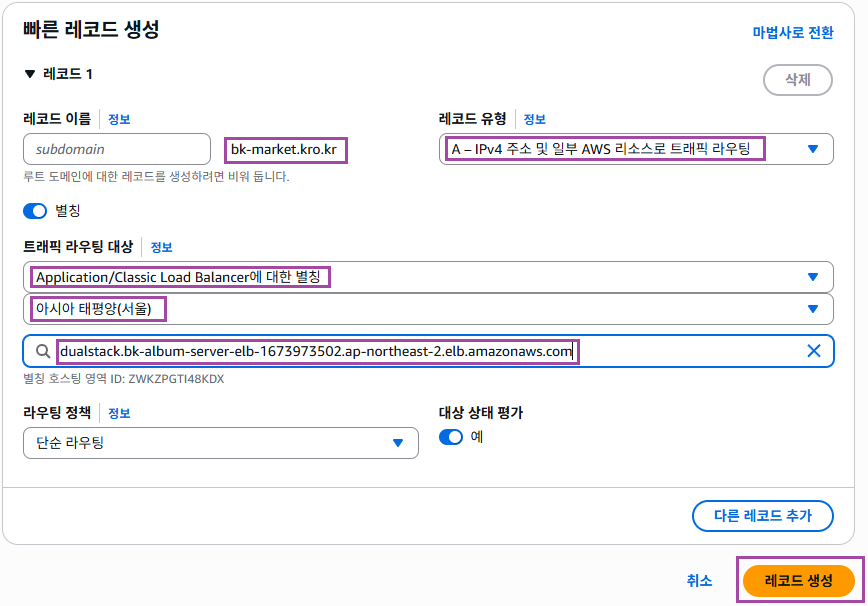
2. 레코드 생성
라우팅 대상을 로드밸런서로 지정한다.
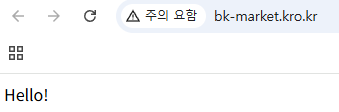
3. 브라우저에서 도메인으로 접속하기
브라우저에서 도메인으로 접속하여 연결된것을 확인
HTTPS 적용을 위한 인증서 발급 받기
HTTPS 를 적용하기 위해서는 인증서를 발급받아야 한다.
1. AWS Certificate Manager 에서 인증서 요청 클릭
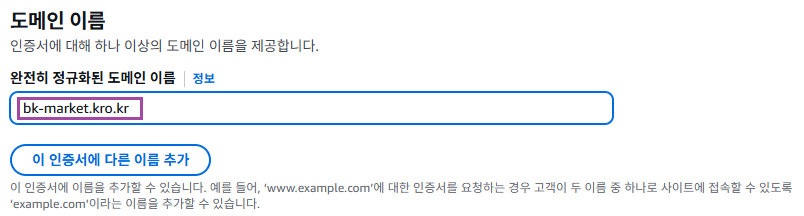
2. 인증서 요청하기
내가 등록한 도메인 이름 지정
다른 설정은 이대로 두고 요청
3. 인증서 검사하기
1. 내가 소유한 도메인이 맞는지 검증해야 한다.
2. DNS 관리 페이지에서 CNAME 레코드 설정하기
레코드를 생성하면 CNAME 이름과 CNAME 값이라는 것이 발급된다.
이것들을 도메인 관리페이지에서 CNAME 으로 등록해줘야 한다.
나는 도메인.한국 이라는 사이트에서 무료로 등록한 도메인을 아래와 같이 등록 하였다.
주의할 점은 CNAME 값에서 마지막 . 을 빼고 등록해줘야 한다. 그렇지 않으면 잘못된 CNAME 형식이라며 등록되지 않는다.
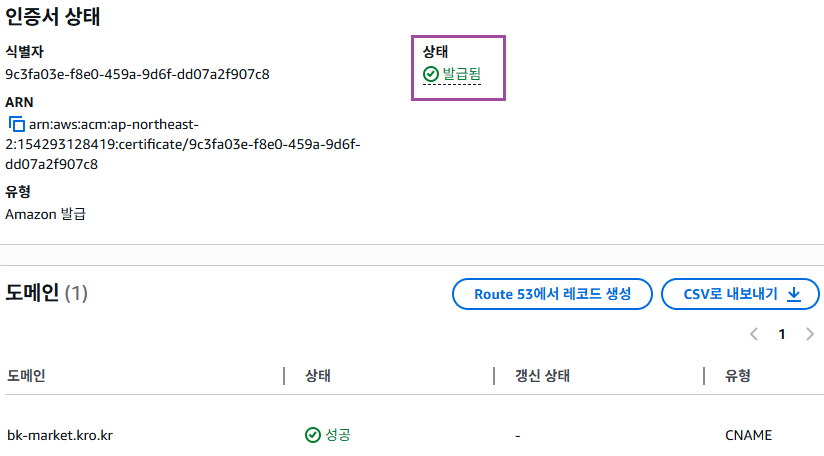
3. 검증 완료
3~10분 정도 기다렸다가 AWS Certifacte Manager 창을 새로고침하면 아래와 같이 검증이 완료된다.
ELB 에 HTTPS 설정하기
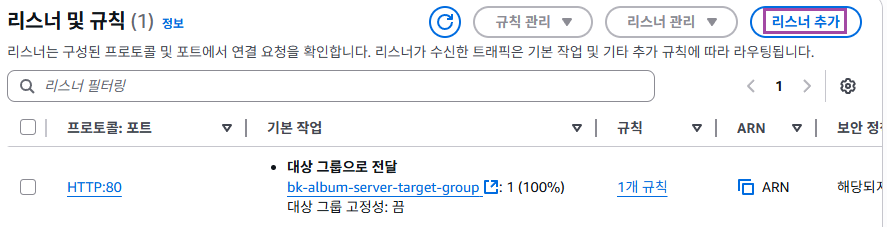
1. ELB의 리스너 및 규칙 수정하기
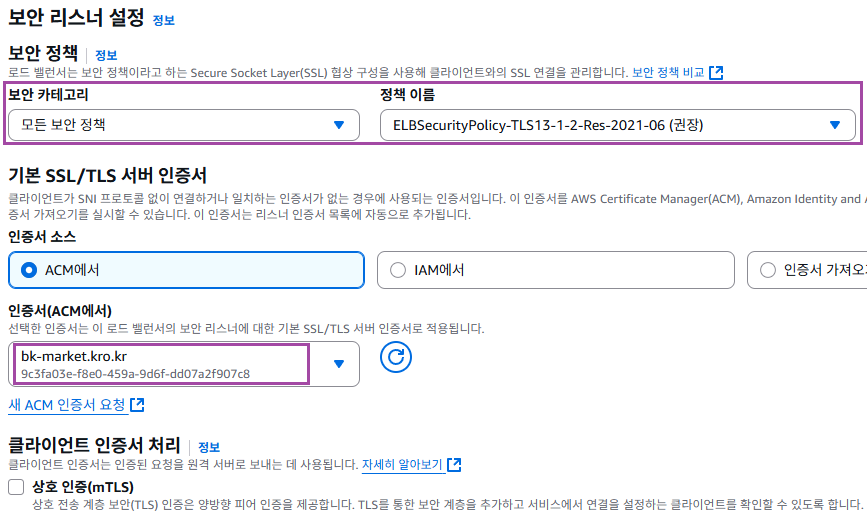
2. DNS 설정에서 CNAME 레코드 ELB DNS 로 지정
위에서 인증서 발급을 위해 CNAME 을 바꿔놨었는데 인증서가 발급되었으니 이제 도메인이 ELB 로 연결되도록 CNAME 을 지정해야 한다.
도메인(Domain) 이 없던 시절에는 특정 컴퓨터와 통신하기 위해서 IP 주소(ex. 12.134.122.11 ) 를 사용했다. 이 IP 는 특정 컴퓨터를 가리키는 주소의 역할을 한다.
하지만 IP 주소는 많은 숫자들로 이루어져 있어서 일일이 외울수가 없다. 이를 해결하기 위해 문자를 IP 주소로 변환해주는 하나의 시스템(서버)을 만들게 되었다. 이게 바로 DNS( Domain Name System ) 이다. DNS가 생기고나서부터 사람들은 특정 컴퓨터와 통신하기 위해 복잡한 IP 주소를 일일이 외울 필요가 없게 되었다.
프론트 웹 페이지든 백엔드 서버든 일반적으로 IP를 기반으로 통신하지 않고 도메인을 기반으로 통신한다. 그 이유는 여러가지있지만 그 이유 중 하나는 HTTPS 적용 때문이다. IP 주소에는 HTTPS 적용 할 수 없다. 도메인 주소가 HTTPS 적용을 할 수 있다. 이 때문에 특정 서비스를 운영할 때 도메인은 필수적으로 사용하게 된다.
무료 도메인 등록 ( 내도메인.한국 )
AWS 에는 도메인을 구매할 수 있는 Route 53 이라는 서비스가 존재한다. 도메인 구매 뿐만 아니라 HTTPS 적용도 할 수있다. 그러나 Route 53 에서 도메인을 구매하면 비용이 비싸기때문에 내도메인.한국 이라는 곳을 이용할 생각이다.
아래 검색창에서 원하는 도메인 주소를 입력 후 검색 후 도메인 검색 결과가 존재한다면 등록하기 버튼만 누르면 정말 간단하게 무료로 도메인을 등록할 수 있다.
아래와 같이 도메인 주소를 등록하였다.
도메인을 EC2 에 연결하기
도메인에 IP 연결하기
연결할 도메인을 선택해 수정버튼을 누르면 아래와 같은 페이지가 나온다. 연결할 IP 를 IP연결(A) 쪽에 등록하면 생성한 EC2와 연결이 된다. 이때 IP 는 EC2와 연결한 탄력적 IP 이다.
연결 확인
bk-market.kro.kr 이라는 도메인으로 브라우저에 접속했을 때 EC2에서 실행한 스프링 부트로 연결된것을 알 수 있다.
배포란 개발 환경에서 만든 애플리케이션을 운영 환경에 올려서 실제로 서비스 할 수 있게 하는 것을 의미한다. 쉽게 말해 다른 사용자들이 인터넷을 통해서 사용할 수 있게 만드는 것을 의미한다. 즉, 우리가 만든 웹 페이지나 서버를 다른 사람들이 사용하려면 인터넷 상에 배포가 돼있어야 한다.
자신의 컴퓨터에서 개발을 할 때는 localhost 라는 주소로 테스트도 하고 개발을 한다. 하지만 이 localhost 는 다른 컴퓨터에서는 접근이 불가능한 주소이다. 배포를 하게 되면 IP(ex. 124.16.2.1) 나 도메인(ex. www.google.com) 과 같이 고유의 주소를 부여받게 되고, 다른 컴퓨터에서 그 주소로 접속할 수 있게 된다. 이것이 바로 배포( Deployment )다.
EC2 란?
EC2 ( Elastic Compute Cloud ) 란?
EC2 란 한 마디로 AWS 에서 제공하는 원격 컴퓨터 임대 서비스이다.
즉, AWS는 돈을 받고 컴퓨터와 다양한 서비스를 제공하고 사용자는 별도의 설치작업 없이 간편하게 원격으로 사용할 수 있는 컴퓨터를 빌릴 수 있고 그외 다양한 서비스를 제공받을 수 있다.
EC2 (Elastic Compute Cloud ) 를 왜 배워야 할까?
서버를 배포하기 위해서는 컴퓨터가 필요하다. 내가 가진 컴퓨터에서 서버를 배포해 다른 사용자들이 인터넷을 통해 접근할 수 있게 만들 수도 있다. 하지만 내 컴퓨터로 서버를 배포하면 24시간 동안 컴퓨터를 켜놓아야 한다. 그리고 인터넷을 통해 내 컴퓨터에 접근할 수 있게 만들다보니 보안적으로도 위험할 수 있다.
이러한 불편함 때문에 내가 가지고 있는 컴퓨터를 사용하지 않고, AWS EC2 라는 컴퓨터를 빌려서 사용하는 것이다. 이 외에도 AWS EC2 는 여러 부가기능들 (로깅, 오토스케일링, 로드밸런싱 등)을 많이 제공한다.
리전(Region) 선택하기
AWS EC2 서비스로 들어가서 리전( Region ) 선택하기
AWS EC2 를 시작하기 위해서는 우선적으로 리전( Region ) 을 먼저 선택해야 한다.
리전 ( Region ) 이란?
리전( Region ) 이란 인프라를 지리적으로 나누어 배포한 각각의 데이터 센터를 의미한다.
우리는 EC2가 컴퓨터를 빌려서 원격으로 접속해 사용하는 서비스 라는 것을 알고 있다. 여기서 EC2를 통해 빌려서 쓸 수 있는 컴퓨터들이 전 세계적으로 다양하게 분포해있다. 이렇게 컴퓨터들이 자리하고있는 위치를 보고 AWS에서는 리전( Region )이라고 한다.
리전( Region )은 어떤 기준으로 선택해야 하나?
사람들이 애플리케이션을 사용할 때는 네트워크를 통해 통신하게 된다. 이 때, 사용자의 위치와 애플리케이션 을 실행시키고 있는 컴퓨터와 위치가 멀면 멀수록 속도는 느려진다. 따라서 애플리케이션의 주된 사용자들의 위치와 지리적으로 가까운 리전( Region ) 을 선택하는 것이 유리하다.
EC2 세팅하기 - 기본 설정
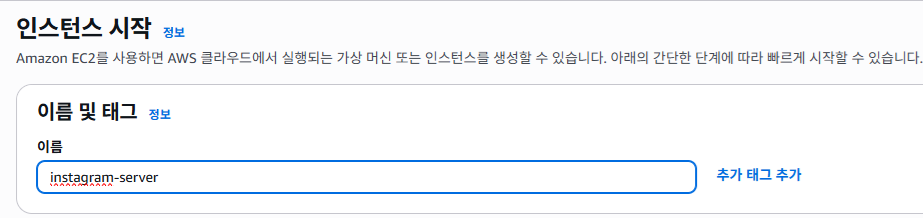
1) 이름 및 태그
EC2의 이름을 설정하는 곳이다. 이름을 지을 때는 이 컴퓨터가 어떤 역할을 하는 지 알아볼 수 있게 작성한다.
2) 애플리케이션 및 OS 이미지 ( Amazon Machine Image )
OS 를 선택하는 단계이다. OS(운영체제)란 Mac, Windows, Linux 같은 것들을 말한다. Windows 나 Mac OS 는 생각보다 용량도 많이 차지하고 성능도 많이 잡아먹는다. 그래서 서버를 배포할 컴퓨터의 OS 는 훨씬 가벼운 Ubuntu 를 많이 사용한다.
3) 인스턴스 유형
우선 인스턴스란, AWS EC2에서 빌리는 컴퓨터 1대를 의미한다.
그럼 인스턴스 유형은 무슨 뜻일까? 컴퓨터 사양을 의미한다. 컴퓨터 사양이 좋으면 좋을수록 많은 수의 요청을 처리할 수 있고, 무거운 서버나 프로그램을 돌릴 수 있다.
프리 티어에 해당하는 t3.micro 를 사용할 것이다.
4) 키 페어( 로그인 )
키 페어( Key Pair )는 무슨 뜻일까? EC2 컴퓨터에 접근할 때 사용하는 비밀번호라고 생각하면 된다. 말 그대로 열쇠( Key ) 의 역할을 한다.
키 페어 이름은 어떤 EC2에 접근하기 위한 키 페어였는 지 알아볼 수 있게 지정하면 좋다.
RSA 와 .pem 을 선택한 후에 키 페어를 생성하면 된다. ED25519 가 뭔지, .ppk 가 뭔지는 나중에 알아보자.
키 페어를 생성하면 파일이 하나 다운받아지는데, 그 파일을 잃어버리지 않도록 잘 보관하자.
EC2 세팅하기 - 보안그룹 설정
네트워크 설정
보안 그룹( Secvurity Group ) 이란?
보안 그룹( Security Group ) 이란 AWS 클라우드에서의 네트워크 보안을 의미한다.
EC2 인스턴스를 집이라고 생각한다면, 보안 그룹은 집 바깥 쪽에 쳐져있는 울타리와 대문이라고 비유할 수 있다.
집에 접근할 때 울타리의 대문에서 접근해도 되는 요청인지 보완 요원이 검사를 하는 것과 비슷하다.
인터넷에서 일부 사용자가 EC2 인스턴스에 접근(액세스) 하려고 한다고 가정해보자. 위 그림과 같이 EC2 인스턴스 주위에 방화벽 역할을 할 보안 그룹( Security Group ) 을 만들고 보안 그룹에 규칙을 지정한다. 이 보안 규칙에는 인바운드 트래픽( 외부에서 EC2인스턴스로 보내는 트래픽 ) 에서 어떤 트래픽만 허용할 것인지 설정할 수 있고, 아웃바운드 트래픽( EC2 인스턴스에서 외부로 나가는 트래픽 ) 에서 어떤 트래픽만 허용할 것인지 설정할 수 있다.
보안 그룹을 설정할 때는 허용할 IP 범위와 포트(port) 를 설정할 수 있다.
그러면 EC2 인스턴스를 생성할 때 어떻게 보안 그룹( Security Group ) 을 설정해야 하는지 알아보자.
보안 그룹 설정
외부에서 EC2로 접근할 포트는 22번 포트와 80번 포트이고 이 2가지 포트에 대해 인바운드 보안 규칙을 추가했다. 왜냐하면 22번 포트는 우리가 EC2에 원격 접속할 때 사용하는 포트이고, 80번 포트는 백엔드 서버를 띄울 예정이기 때문이다. 그리고 어떤 IP 에서든 전부 접근할 수 있게 만들기 위해 소스 유형은 위치 무관으로 설정했다.
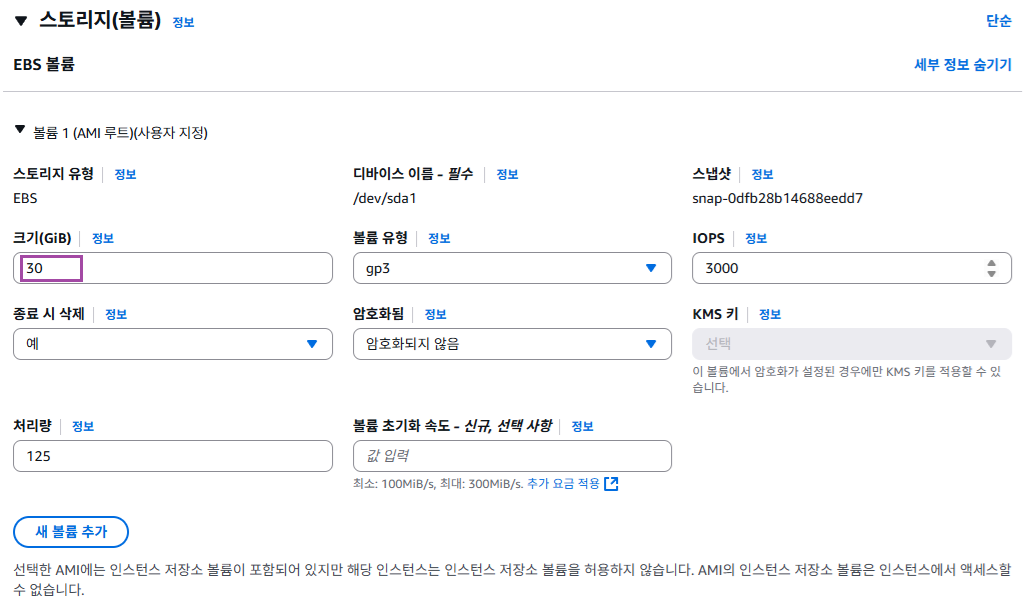
EC2 세팅하기 - 스토리지 구성
스토리지 구성
우리가 쓰고 있는 노트북이나 데스크탑 컴퓨터는 하드디스크를 가지고 있다. 하드디스크는 컴퓨터에 파일을 저장하는 공간이다. EC2 도 하나의 컴퓨이다보니 여러 파일들을 저장할 저장 공간이 필요하다. 이 저장 공간을 보고 EBS( Elastic Block Storage ) 라고 부른다. EBS와 같은 저장 공간을 조금 더 포괄적인 용어로 스토리지(Storage), 볼륨(Volume) 이라고 부른다.
스토리지의 종류를 보면 gp3 이외에도 여러가지 종류의 스토리지가 있다. 하지만 가성비가 좋은 gp3 를 선택하자. 용량을 30GiB를로 설정하는 이유는 프리 티어에서 30GiB까지 무료로 제공해주기 때문이다. 이 스토리지의 크기는 추후에 늘릴 수도 있으므로 처음 설정할 때 너무 큰 고민을 할 필요는 없다.
EC2 접속하기
생성된 인스턴스 정보 해석하기
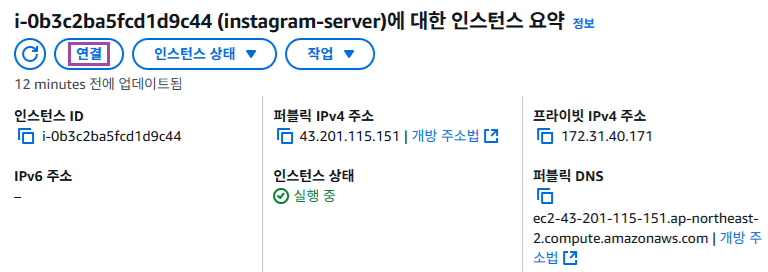
1) 세부 정보
세부 정보에서 눈여겨 봐야할 부분은 2가지 이다. 퍼블릭 IPv4 주소와 인스턴스 상태이다.
퍼블릭 IPv4 주소는 EC2 인스턴스가 생성되면서 부여받은 IP 주소이다. EC2 인스턴스에 접근하려면 이 IP주소로 접근하면 된다.
인스턴스 상태는 말그대로 EC2 인스턴스가 실행 중이라는 뜻은 컴퓨터가 켜져있다는 의미이다.
EC2 인스턴스를 중지, 재부팅, 종료(삭제) 할 수도 있다.우리가 쓰는 컴퓨터와 비슷하다. 재부팅은 말그대로 컴퓨터를 재시작시키는 것을 의미하고 중지는 컴퓨터를 잠시 꺼놓는 것을 의미한다. 종료는 컴퓨터를 아예 삭제시킨다는 것을 의미한다. EC2 인스턴스를 한번 종료하면 도중에 취소할 수 없으니 조심해야 한다.
2) 보안 (보안 그룹)
인스턴스 생성 시 설정한 보안 그룹에 대한 정보가 표시된다.
3) 네트워크
퍼블릭 IPv4 주소는 생성한 EC2 인스턴스의 IP 주소를 뜻한다.
4) 스토리지
인스턴스 생성 시 설정한 스토리지에 대한 정보가 나온다.
5) 모니터링
EC2 인스턴스가 정상적으로 작동하고 있는지, EC2 인스턴스의 성능을 향상시켜주어야 하는것은 아닌지 아래 지표를 통해 파악할 수 있다.
EC2 인스턴스 모니터링 예
EC2에 접속하기
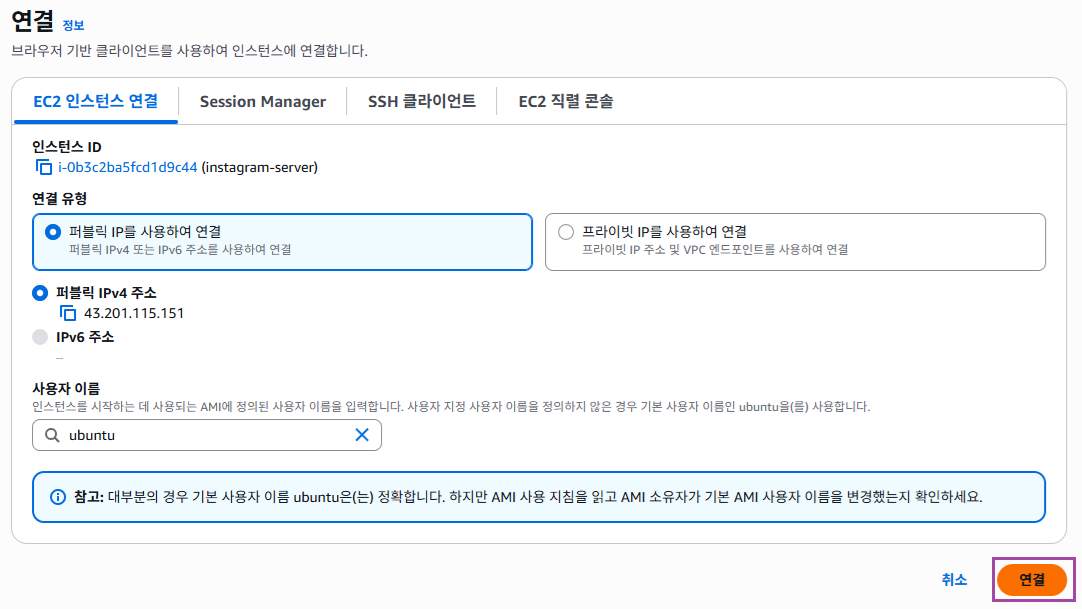
이전에 생성한 키, 페어로 접속할 수도 있지만 좀 더 간편한 방식인 브라우저로 접속하겠다. 인스턴스 탭에서 실행중인 인스턴스를 클릭하고 연결 버튼만 클릭하면 EC2로 간단하게 접속할 수 있다.
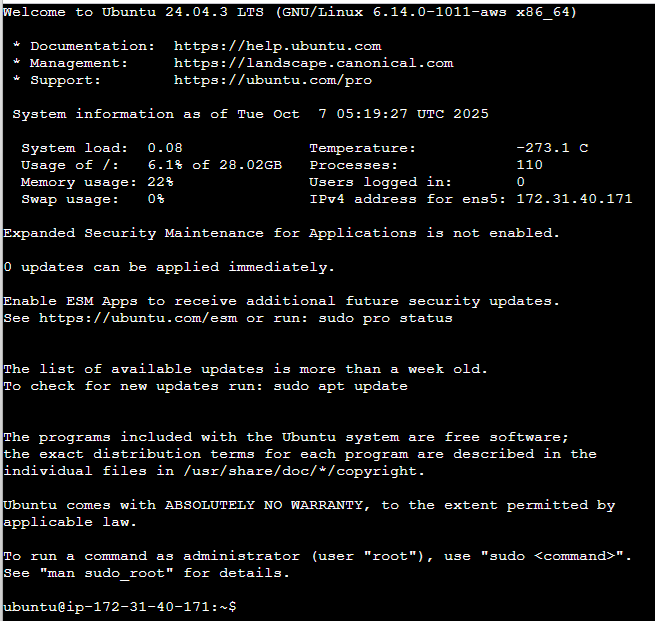
EC2 접속하여 Ubuntu Linux 첫 화면
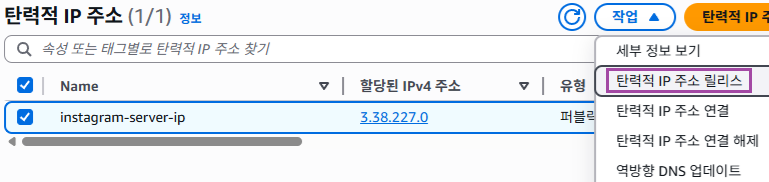
탄력적 IP 연결하기
탄력적 IP 란?
EC2 인스턴스를 생성하면 IP를 할당받는다. 하지만 이렇게 할당받은 IP는 임시적인 IP이다. EC2 인스턴스를 잠깐 중지시켰다가 다시 실행시켜보면 IP가 바뀌어있다. 그래서 중지시켰다가 다시 실행시켜도 바뀌지 않는 고정 IP 를 할당받아야 한다.
그것이 바로 탄력적 IP 이다.
탄력적 IP 설정 방법
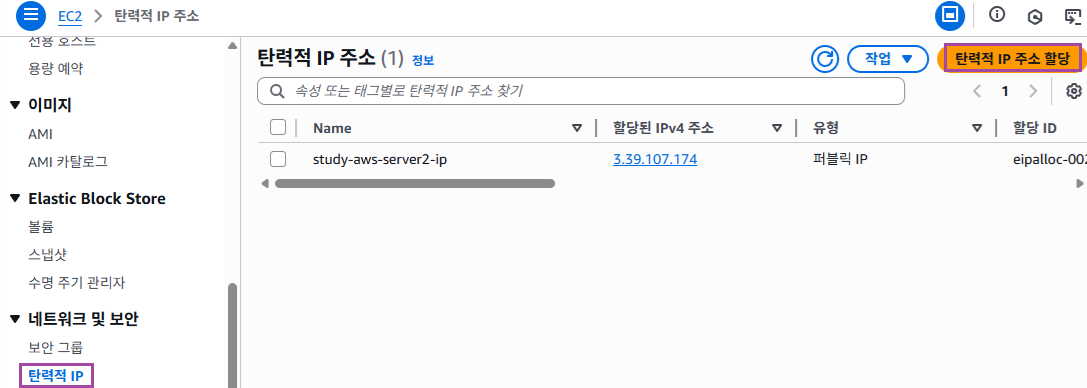
왼쪽 네트워크 및 보안 탭에서 탄력적 IP 를 클릭하고 탄력적 IP 주소 할당을 클릭한다.
할당 버튼을 누른다.
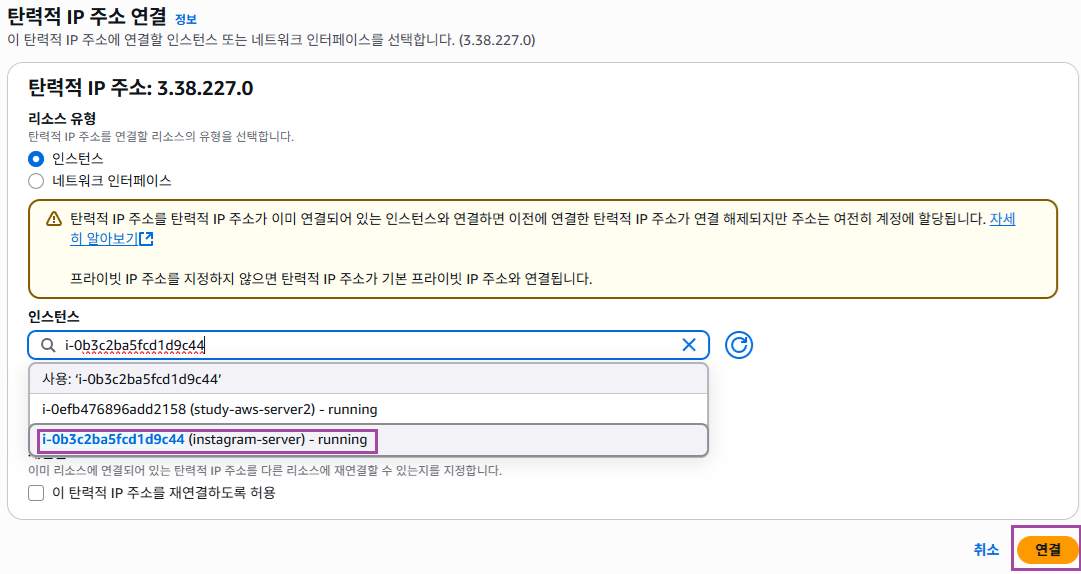
할당받은 IP 의 이름을 지어주고 작업 탭에서 탄력적 IP 주소 연결을 클릭한다.
생성해 놓은 인스턴스를 클릭하여 설정하고 연결버튼 클릭
Spring Boot 서버를 EC2에 배포하기
1) Ubuntu 환경에서 JDK 설치하는 법
Spring Boot 3.xx 버전을 사용할 예정이고, JDK 는 17버전을 사용할 예정이다. 그에 맞게 환경을 설치해보자.
# apt 패키지 업데이트 후 jdk 17 버전 설치
$ sudo apt update && sudo apt install openjdk-17-jdk -y
2) 설치 확인
$ java -version
3) Github 으로부터 Spring Boot 프로젝트 clone 하기
$ git clone https://github.com/JSCODE-EDU/ec2-spring-boot-sample.git
$ cd ec2-spring-boot-sample
4) application.yml 파일 직접 만들기
application.yml 와 같은 민감한 정보가 포함된 파일은 Git 으로 버전 관리를 하지 않는것이 일반적이다. 따라서 application.yml 파일은 별도로 EC2 인스턴스에 올려주어야 한다. 하지만 application.yml 파일을 EC2 인스턴스에 올리는 작업보다는, application.yml 파일을 직접 만드는 게 훨씬 간단하다.
src/main/resources/application.yml
sever: port: 80
5) 서버 실행시키기
$ ./gradlew clean build # 기존 빌드된 파일을 삭제하고 새롭게 JAR로 빌드
$ cd ~/ec2-spring-boot-sample/build/libs
$ sudo java -jar ec2-spring-boot-sample-0.0.1-SNAPSHOT.jar
6) 브라우저로 확인하기
할당 받은 탄력적 IP 로 접속할 수 있다. 그리고 HTTP 요청의 기본포트는 80이기 때문에 뒤에 :80 이 생략되어있다고 할 수 있다.
리눅스 명령어에서 echo 는 Java에서의 System.out.println() , Javascript 에서의 console.log() 와 같은 역할을 하는 명령어이다.
$ echo 1234
$ echo abcd # 숫자, 문자 상관없이 전부 다 입력 가능
$ echo study linux # 띄어쓰기가 있어도 입력 가능
$ echo "ㄱㄴㄷㄹ" # 쌍따옴표로 묶어서도 입력 가능
2. 쉘 스크립트 파일 작성/실행 방법
쉘 스크립트 파일 작성/실행 방법
1) 파일명을 .sh 로 끝나게 작성하기
$ vi first.sh
파일명이 .sh 로 끝나게 작성하지 않아도 쉘 스크립트는 정상적으로 작동한다. 하지만 파일명만 보고 쉘 스크립트 파일인지 바로 알아볼 수 있게, 파일명을 .sh 로 끝나게 작성하는 것
2) 파일 첫 줄에 #!/bin/bash 작성하기
first.sh
#!/bin/bash
위 코드는 해당 스크립트를 어떤 쉘(shell) 로 실행할 지를 명시하기 위해 작성한다. 구체적으로 말하면 '이 파일은 bash 쉘로 해석해서 실행하라' 라는 의미이다. 쉘(shell) 이 뭔지, 다양한 쉘(shell) 에는 어떤 것들이 있는지는 다음에 알아보기로 하자.
3) 자동으로 실행시키고 싶은 명령어들 순서대로 입력하기
first.sh
#!/bin/bash
echo 1
echo 2
echo 3...
위와 같이 입력하고 파일을 저장하고 나오자.
4) 쉘 스크립트 파일 실행하기
아래와 같이 실행시키고자 하는 파일의 경로를 명령어로 입력하면 된다.
$ ./first.sh
하지만 명령어를 입력해보면 Permission denied 라고 에러가 뜬다.
Permission denied 에러 분석하기
$ ls -l first.sh # first.sh 에 대한 파일 세부 정보 확인하기
first.sh 파일의 권한이 rw-rw-r-- 으로 설정되어있다. 따라서 ubuntu 사용자로 접근하면 rw- 권하만 가지고 있고 x 에 대한 권한이 없으므로 실행되지 않는다.
아래와 같이 chmod 를 이용하여 권한을 변경하자.
$ chmod +x first.sh # 모든 사용자에게 실행 권한(x) 을 추가
$ ls -l first.sh # 권한 확인
다시 쉘 스크립트 파일을 실행 해보자.
정상적으로 쉘 스크립트 파일이 실행됐음을 확인할 수 있다. 쉘 스크립트 파일에 작성한 명령어들이 순차적으로 실행 되었다.
쉘 스크립트의 역할
위에서 처럼 쉘 스크립트는 작성한 리눅스 명령어들을 순서대로 실행시키는 역할을 한다. 이 덕분에 여러 복잡한 명령어들을 쉘 스크립트 파일 하나로 간단하게 실행시킬 수 있다. 그래서 어떤 작업을 자동화하기 위해 쉘 스크립트를 활용한다.
3. 쉘 스크립트를 통해 자동화 해보기
'git pull 받아오기 → Spring Boot 빌드 → 빌드된 jar 파일 실행' 의 과정을 자동화 해보기
백엔드 서버를 배포하는 과정을 자동화 해보자. 수동으로 백엔드 서버를 배포할 때 입력하는 리눅스 명령어를 차례대로 쉘 스크립트 파일에 작성하면 된다.
1. 쉘 스크립트 파일 생성
$ cd ~
$ vi deploy.sh
2. 쉘 스크립트 파일 작성
#!/bin/bash
echo "----git pull 받아오기----"
cd /home/ubuntu/linux-springboot
git pull origin main
echo "----빌드하기----"
./gradlew clean build
echo "----빌드된 jar 파일을 백그라운드로 실행시키기----"
cd build/libs
nohup java -jar linux-springboot-0.0.1-SNAPSHOT.jar >> app.log 2>&1 &
echo "----Spring Boot 서버 실행 완료----"
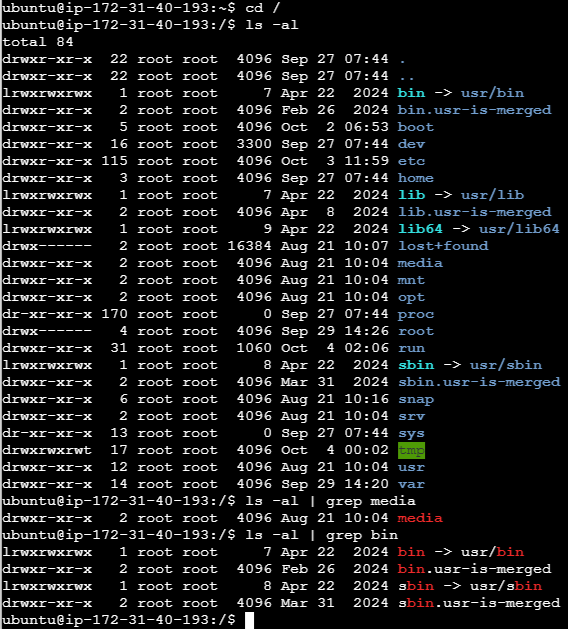
$ cd /
$ ls -al
$ ls -al | grep media # ls -al 의 출력값 중에서 media가 들어간 문장만 출력
$ ls -al | grep bin # ls -al의 출력값 중에서 bin이 들어간 문장만 출력
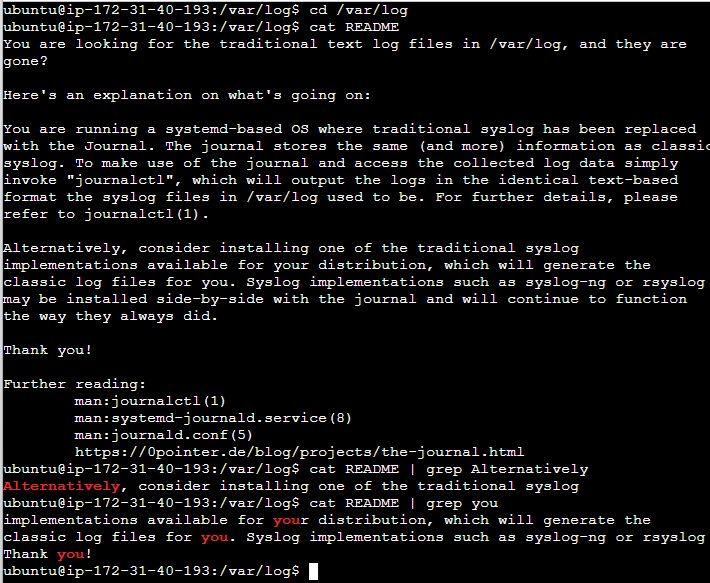
$ cd /var/log
$ cat README
$ cat README | grep Alternatively # cat의 출력값 중에서 Alternatively 가 들어간 문장만 출력
$ cat README | grep you # cat의 출력값 중에서 you 가 들어간 문장만 출력
2. 리눅스에서 실행 중인 프로세스 조회하기 / 종료하기 (ps, kill)
프로세스란?
프로세스(process) 란 실행 중인 프로그램을 의미한다. 일반적으로 프로그램(program)이라는 용어가 익숙할 것이다. 하지만 운영체제를 학습하는데 있어서 프로세스(process) 라는 용어를 더 자주 쓰게 될 것이다. 왜냐하면 운영체제가 다루는 대상이 '저장된 코드'가 아니라 '실행 중인 코드'이기 때문이다. 프로그램(program) 이란 디스크 등에 저장된 실행 파일을 의미하고 프로세스(process)란 실행중인 프로그램의 인스턴스 메모리와 CPU 자원을 실제로 점유하는 "실행 단위" 를 의미한다.
리눅스에서 실행 중인 프로세스 조회하기
리눅스에서도 윈도우에서 처럼 작업 관리자 창과 같이 실행 중인 프로그램들을 확인할 수 있는 명령어가 있다.
# 실행 중인 모든 프로세스 조회
$ ps aux
USER : 프로세스를 실행한 사용자
PID : 프로세스를 식별하기 위한 ID (Process ID)
%CPU : CPU 사용률
%MEM : 메모리 사용률
COMMAND : 프로세스를 실행할 때 사용한 명령어를 보여줌 → 어떤 프로세스인지 쉽게 파악할 수 있음
하지만 모든 프로세스를 조회하다보니 보기가 불편하다. 그래서 아래와 같이 특정 키워드가 포함된 문장만 출력하게끔 명령어를 사용할 수 있다.
# 예시
$ ps aux | grep amazon
프로세스 종료하기
ps aux 명령어를 통해 실행 중인 프로세스를 조회한 뒤에, 종료하고자 하는 프로세스의 PID 값을 활용해서 종료하면 된다.
$ kill [PID 값]
3. 실행시킨 Spring Boot 프로세스를 조회하고 종료해보기
실행시킨 Spring Boot 프로세스를 조회하고 종료해보기
1) Spring Boot 서버 실행
$ cd ~/linux-spring/build/libs
$ java -jar linux-springboot-0.0.1-SNAPSHOT.jar
2) 잘 작동하는지 확인
http://{EC2 인스턴스의 Public IP 주소}:8080 주소로 접속
3) 새로운 터미널 창 열어서 프로세스 조회해보기
Spring Boot 서버를 실행시킨 채로 다른 명령어를 입력하려고 해도 작동하지 않기 때문에 새로운 터미널 창을 열어주자. ( 브라우저 새 탭에서 리눅스가 켜진 탭의 url 주소를 복사하면 새로운 터미널 창을 열수 있다.) 그리고 다음 명령어를 입력하여 실행 중인 프로세스를 조회해보자.
$ ps aux
출력값을 살펴보면 익숙한 명령어 ( java -jar linux-springboot-0.0.1-SNAPSHOT.jar ) 가 보인다. 프로세스를 실행할 때 사용한 명령어가 출력된 것이다. 이 프로세스가 바로 Spring Boot 의 프로세스이다.
하지만 실행중인 프로세스가 많다면 눈으로 찾기가 힘들다. 그래서 아래 명령어를 이용해 빠르게 실행 중인 Spring Boot 프로세스를 찾을 수 있다.
$ ps aux | grep java
이 명령어는 Spring Boot 서버를 실행한 이후에 프로세스가 죽지 않고 정상적으로 잘 실행됐는지를 확인할 때도 사용할 수 있다.
4) Spring Boot 프로세스 종료하기
실행 중인 Spring Boot 서버를 종료하기 위해서는 아래 명령어를 이용해 실행 중인 Spring Boot 프로세스의 PID 를 먼저 알아내야 한다.
$ ps aux | grep java
그 다음 PID를 이용해 아래와 같이 프로세스를 종료하는 명령어를 실행시키면 된다.
$ kill 56021
5) 정상적으로 종료되었는지 확인하기
a. Spring Boot 서버를 실행시킨 터미널 창 확인하기
b. IP 주소로 접속해보기
c. 프로세스 조회해보기
$ ps aux | grep java
java -jar ... 로 시작하는 COMMAND 를 가진 프로세스는 조회되지 않는다. 즉 실행되고 있는 Spring Boot 서버는 없다는 뜻이다.
4. 터미널 창을 끄더라도 프로그램이 계속 실행되도록 만들기 ( nohup, & )
포그라운드( foreground ), 백그라운드( background ) 란?
포그라운드( foreground ) 는 내가 실행시킨 프로그램의 내용이 화면에서 실행되고 출력되는 상태를 뜻한다. 그러다보니 포그라운드 상태에서는 다른 프로그램을 조작할 수가 없다.
백그라운드 ( background ) 는 내가 실행시킨 프로그램이 컴퓨터 내부적으로 실행되는 상태를 의미한다. 그래서 프로그램이 어떻게 실행되고 있는지에 대한 정보가 화면에 자동으로 출력되지는 않는다. 이런 특성 때문에 다른 명령어를 추가로 입력할 수도 있고, 새로운 프로그램을 조작할 수도 있다.
백그라운드( background ) 로 Spring Boot 를 실행시켜 보자
1) Spring Boot 를 백그라운드에서 실행하기
프로세스를 백그라운드에서 실행시키려면 명령어의 앞 부분에 nohup 을 붙이고, 뒷 부분에 & 를 붙이면 된다.
백그라운드에서 Spring Boot 를 실행시켜보면 포그라운드와 달리 실시간으로 로그가 찍히지 않는다.
그렇다면 Spring Boot 가 출력하는 로그는 어디에서 확인해야 하는가?
nohup 이라는 명령어로 프로그램을 실행시키면 nohup.out 이라는 파일에 로그가 쌓이게끔 작동한다. nohup 명령어를 입력한 뒤에 찍히는 출력값을 자세히 읽어보면 아래와 같이 작성되어 있다.ㅣ
... appending ouput to 'nohup.out'
프로세스에서 발생한 출력값을 nohup.out 이라는 파일에 추가해서 저장하겠다는 의미이다. 실제로 그런지 확인해 보자.
4) nohup.out 파일 확인해 보기
확실한 테스트를 위해 기존에 실행시키던 Spring Boot 서버를 종료하고 기존 nohup.out 파일을 삭제한 뒤에 확인해 보자.
# Spring Boot 프로세스 종료하기
$ ps aux | grep java
$ kill [PID 값]
# 기존 nohup.out 파일 삭제
$ ls
$ rm -rf nohup.out
$ ls # 잘 삭제되었는지 확인
# 백그라운드에서 Spring Boot 실행시키기
$ nohup java -jar linux-springboot-0.0.1-SNAPSHOT.jar &
$ ls # nohup.out 파일 생성되었는지 확인
$ cat nohup.cat # 파일 확인해보기
nohup.out 파일을 확인해보면 백그라운드에서 실행된 프로세스의 로그가 파일에 기록된 것을 확인할 수 있다.
그렇다면 nohup.out 파일 말고 다른 파일에 로그를 남기려면 어떻게 해야할까?
nohup.out 파일이 아닌 다른 파일에 로그가 남도록 만들기
$ rm -rf nohup.out # 확실한 테스트를 위해 기존 nohup.out 파일 삭제
$ nohup java -jar linux-springboot-0.0.1-SNAPSHOT.jar >> result.log 2>&1 &
$ ls
$ cat result.log
Sprint Boot 프로세스에서 발생한 로그 (표준 출력과 표준 에러 출력) 를 result.log 파일로 전달하게 만드는 명령어이다. 그리고 > 대신에 >> 를 쓴 이유는 파일을 매번 새로 덮어쓰는 것이 아닌, 기존 파일에 이어서 로그를 쌓아가게끔 만들고 싶어서이다. 아래에서 result.log 파일을 확인해보면 정상적으로 로그가 저장된 것을 확인할 수 있다.
위의 로그를 잘 살펴보면 Port 8080 was already in use 라는 에러 메시지가 로그로 남아있다. 아래에서는 왜 이런 에러 메시지가 뜨고 해결하는 방법에 대해서 알아보자.
6. 특정 포트 번호에 실행되고 있는 프로세스 조회하기 / 포트 충돌 해결하기 ( lsof )
포트( Port ) 란?
포트( Port )란 한 컴퓨터 내에서 실행되고 있는 특정 프로그램의 주소를 의미한다.
하나의 컴퓨터에는 총 65536개 (0 ~ 65535)의 포트 번호를 가지고 있다. Spring Boot 와 같은 백엔드 서버를 실행시킬 때 어떤 포트에서 실행시킬 지 정해야 한다. 만약 아무런 설정을 하지 않으면 Spring Boot 는 기본적으로 8080번 포트에서 실행되도록 작동한다.
주의할 점은 하나의 포트에는 단 하나의 프로세스만 실행시킬 수 있다는 점이다. 예를 들어, 8080번 포트에 이미 Spring Boot 서버가 실행되고 있다고 가정하자. 그런데 Node.js 서버를 8080번 포트에 띄우려고 하면 에러가 발생한다. 왜냐하면 8080 포트에 이미 Spring Boot 프로세스가 실행되고 있기 때문이다.
에러 원인 해석하기
Port 8080 was alread in use
→ 8080번 포트를 이미 사용하고 있다고 한다. 즉, 8080번 포트에서 어떤 프로그램이 이미 실행되고 있다는 뜻이다. 그래서 Spring Boot 를 실행시키려고 하는데 에러가 발생한 것이다.
그렇다면 8080번 포트에서 어떤 프로그램이 실행되고 있는지 확인하려면 어떻게 해야 할까?
특정 포트 번호에 실행되고 있는 프로세스 조회하기
# sudo lsof -i:[포트번호]
$ sudo lsof -i:8080
주의) sudo 를 붙여야만 시스템 내의 모든 프로세스를 기반으로 특정 프로세스를 조회해준다.
8080번 포트에 실행되고 있는 프로세스가 조회됐다. 조회된 프로세스에서 2가지 항목을 살펴보자.
COMMAND : 프로세스를 실행시킬 때 사용한 명령어의 '일부'만 보여준다.
PID : 프로세스를 식별하기 위한 ID
여기서 어떤 프로세스인지 COMMAND 의 값의 일부인 java 라는 키워드만 보고 유추할 수 있다면 상관없는데, 정확히 어떤 프로세스인지 모르겠다 싶을 땐 COMMAND 의 전체를 볼 필요가 있다.
그럴 땐 COMMAND 의 전체 값을 보여주는 ps aux 명령어를 활용하면 된다. 아래 명령어를 이용해 PID 가 58158 인 프로세스만 찾아 조회하는 것이다.
# 실행 중인 모든 프로세스 조회 + 58158 라는 키워드가 들어간 문장만 출력
$ ps aux | grep 58158
그러면 구체적으로 어떤 명령어를 통해 프로세스를 실행시킨지 파악할 수 있고, 그럼으로써 어떤 프로세스가 실행되고 있는지 좀더 명확하게 파악할 수 있다.
특정 포트 번호에 실행되고 있는 프로세스 종료하기
8080번 포트에 내가 원하는 프로세스를 실행시키기 위해, 기존에 8080번 포트에 실행되고 있는 프로세스를 종료시켜보자.
# sudo lsof -i:[포트번호]
$ sudo lsof -i:8080
위 명령어를 통해 8080번 포트에서 실행되고 있는 프로세스의 PID 값을 알아내고 kill 명령어를 통해 프로세스를 종료시키면 된다.
$ kill 58158
정상적으로 프로세스가 잘 종료 되었는지 확인
$ sudo lsof -i:8080
7. 서버가 잘 작동하는 지 API 요청 보내보기 ( curl )
서버가 잘 작동하는 지 API 요청 보내보기 ( curl )
실제 백엔드 서버를 띄우고나서 테스트 할 때 많이 활용하는 툴로 포스트맨( Postman)이 있다. 포스트맨 (Postman) 을 활용하면 다양한 형태의 API 요청을 보낼 수 있어 테스트하기가 용이하다.
리눅스에서도 포스트맨(Postman) 과 같은 역할을 하는 curl 이라는 명령어가 있다. curl 명령어를 활용하면 GET , POST , PUT , DELETE 등 포스트맨(Postman)처럼 다양한 형태로 요청을 보낼 수 있다.
[예시]
# GET 형식
$ curl http://example.com/api/data
# POST 형식
$ curl -X POST http://localhost:8080/api/users \
-H "Content-Type: application/json" \
-d '{"name": "홍길동", "email": "gildong@example.com"}'
# PUT 형식
$ curl -X PUT http://localhost:8080/api/users/1 \
-H "Content-Type: application/json" \
-d '{"name": "홍길동", "email": "gildong@example.com"}'
# 등등
그런데 위 예시를 보면 GET 요청을 제외하고는 명령어가 다소 복잡하기 때문에, 간단하게 GET 요청으로만 API 를 테스트하면 될 때에만 curl 을 사용한다.
1. 리눅스 환경에서 실행시킨 서버가 정상적으로 작동하는 지 체크하고 싶을 때
$ curl localhost:8080 # Spring Boot 서버가 내부에서 잘 실행되고 있는 지 체크
$ curl [EC2 퍼블릭 IP]:8080 # Spring Boot 서버가 외부 IP로도 요청이 되는 지 체크
$ curl localhost:9999 # 잘못된 주소로 요청보내보기
브라우저에서 직접 켜서 테스트해보거나 포스트맨을 켜서 테스트 할 필요없이 간단하게 curl 명령어를 이용하여 테스트해볼 수 있다.
2. 외부의 API 서버가 잘 작동하는지 체크하고 싶을 때
$ curl https://jsonplaceholder.typicode.com/posts # 샘플 API 주소
8. 내 IP 주소 확인하기 ( ip )
내 IP 주소 확인하기 ( ip )
IP 란 네트워크 상에서의 특정 컴퓨터를 가리키는 주소를 의미한다. 아래와 같은 값이 IP 주소이다.
13.250.15.132
AWS에서 제공하는 터미널 창에서는 Public IP 와 Private IP를 둘 다 알려준다. 하지만 일반적인 터미널 창에서는 IP를 표시해주지 않기 때문에, IP를 명령어로 알아낼 수 있어야 한다.
cf) Public IP, Private IP란? - Public IP : 외부 인터넷을 통해 접근할 수 있는 IP - Private IP : 같은 네트워크 안에서만 접근할 수 있는 IP
[Public IP 주소 알아내는 법]
$ curl ifconfig.me
이전에 curl 에 대해 설명했다. curl 은 특정 주소로 API 요청을 보낼 때 사용하는 명령어라고 얘기했다. 위 명령어는 ifconfig.me 라는 URL 로 GET 요청을 보내는 명령어다. ifconfig.me 라는 사이트는 내 컴퓨터의 IP 주소를 알려주는 사이트다.
브라우저에서 ifconfig.me 주소로 접속해봐도 IP 주소를 알려준다는 것을 확인할 수 있다.
[Private IP 주소 알아내는 법]
$ ip a
ip a 명령어를 입력한 뒤 2번째 inet 뒤에 있는 값이 Private IP 주소이다.
9. 컴퓨터가 느려질 때 CPU, Memory 성능 체크해서 원인 파악하기 ( top )
컴퓨터가 느려질 때 CPU, Memory 성능 체크하기 ( top )
우리가 사용하는 컴퓨터도 동시에 여러 프로그램을 많이 키면 속도가 느려질 때가 있다. 그럴 때 작업 관리자 창을 켜서 어떤 프로그램이 렉을 걸리게 하는 지 파악할 수 있다. 컴퓨터는 CPU나 메모리가 부족하면 렉이 걸리기 때문에 CPU 또는 메모리의 사용률이 높은 프로그램이 컴퓨터를 느려지게 만든 프로그램일 가능성이 높다.
이처럼 리눅스 운영체제에서도 작업 관리자 창처럼 CPU 와 메모리 성능을 체크할 수 있는 기능이 있다. 아래의 명령어를 입력해서 실행시켜보자.
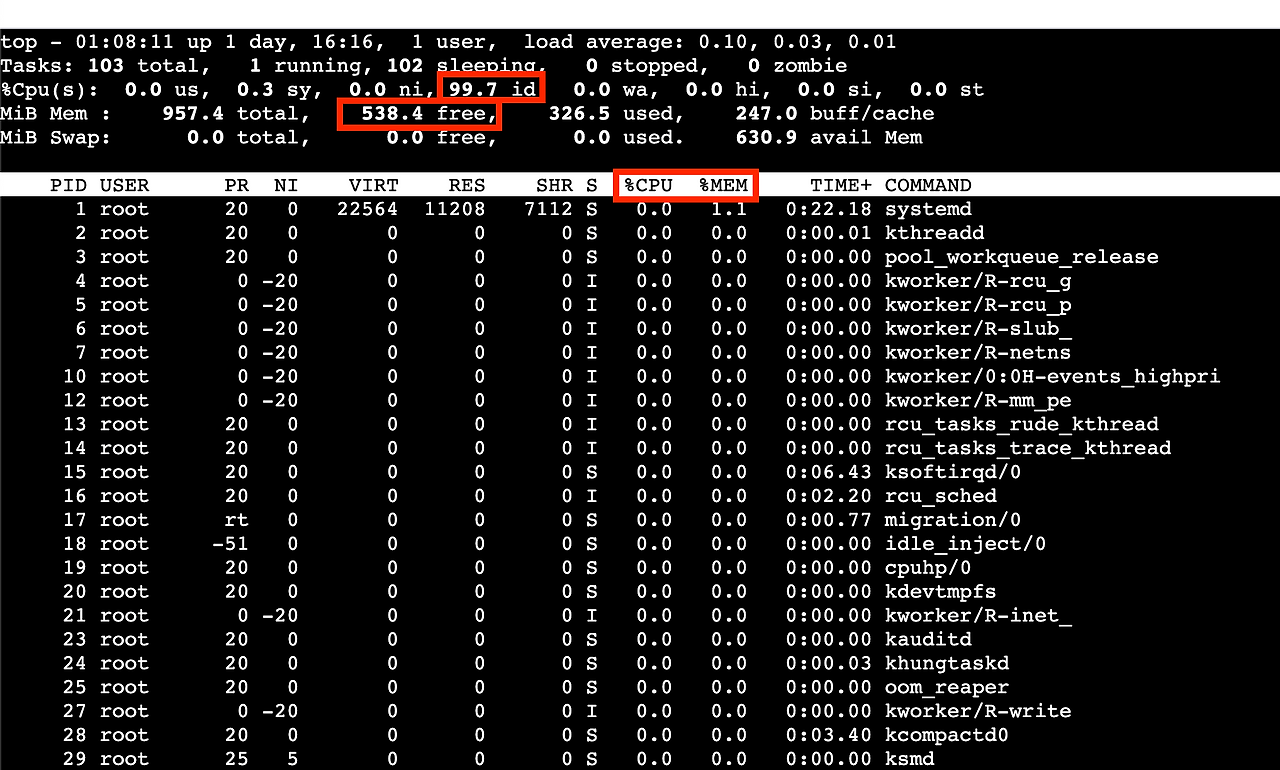
$ top
%CPU(s) 의 항목에서 id 부분의 값이 CPU 의 여유 정도를 나타낸다. 99.7 id 라는 뜻은 컴퓨터에서 여유로운 CPU 비중이 99.7% 라는 뜻이다. 만약 이 값의 숫자가 작다면 컴퓨터가 버벅거릴 가능성이 크다.
Mib Mem 의 항목에서 free 부분의 값은 남아있는 메모리의 크기를 나타낸다. 538.4 free 라는 뜻은 539.4MB 만큼의 사용할 수 있는 여분의 메모리가 있다는 뜻이다. 만약 이 값의 숫자가 0에 가깝다면 컴퓨터가 버벅거릴 가능성이 있다.
1,2번의 수치를 확인했을 때 CPU 또는 메모리가 부족하다면 어떤 프로세스에서 CPU랑 메모리를 많이 잡아먹고 있는 지 파악해야 한다. 나열되어 있는 프로세스 중 CPU 또는 메모리의 사용률이 높은 프로세스가 있는지 체크하고 PID를 이용해 종료시키면 된다. 편리하게도 top 명령어가 CPU 사용률이 높은 프로세스를 알아서 상위로 노출시켜준다.
10. 로그 실시간으로 확인하는 법 (tail -f )
로그 실시간으로 확인하는 법 ( tail - f )
AWS EC2 에서 만든 Ubuntu 컴퓨터에서 접속할 때마다 로그가 쌓이는 /var/log/auth.log 라는 파일이 있다. 그 파일을 먼저 열어서 살펴보자.
$ cd /var/log
$ ls
$ vi auth.log # ctrl +f, ctrl + b 명령어를 통해 파일을 살펴보자
지금까지 쌓인 로그를 볼 때는 위 명령어로 볼 수 있지만 현재 실시간으로 로그가 어떻게 쌓이고 있는 지 봐야할 수도 있다. 그럴 땐 아래의 명령어를 사용하면 된다.
# tail -f [파일명]
$ tail -f auth.log # 파일의 마지막 10줄을 출력 + 실시간으로 파일에 추가되는 내용을 출력
위 명령어를 입력한 채 새로운 브라우저 창에서 Ubuntu 컴퓨터에 접속해보자.
새로운 브라우저 창에서 Ubuntu 컴퓨터에 접속하는 순간 로그가 쌓이는 것을 실시간으로 확인할 수 있다. 그리고 새로운 브라우저 창에서 계속 새로고침 할 때마다 로그가 쌓인다.
이와 같이 특정 파일에 로그가 실시간으로 어떻게 쌓이는지 확인하고 싶을 때는 tail -f 명령어를 사용하면 된다.
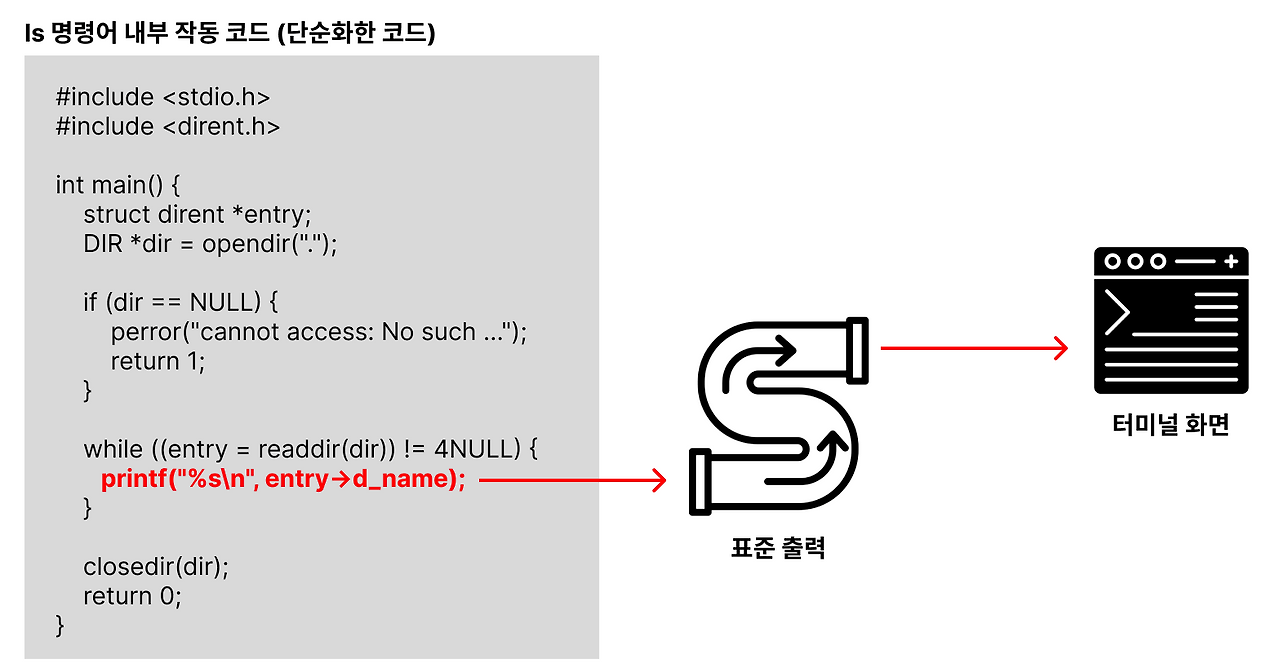
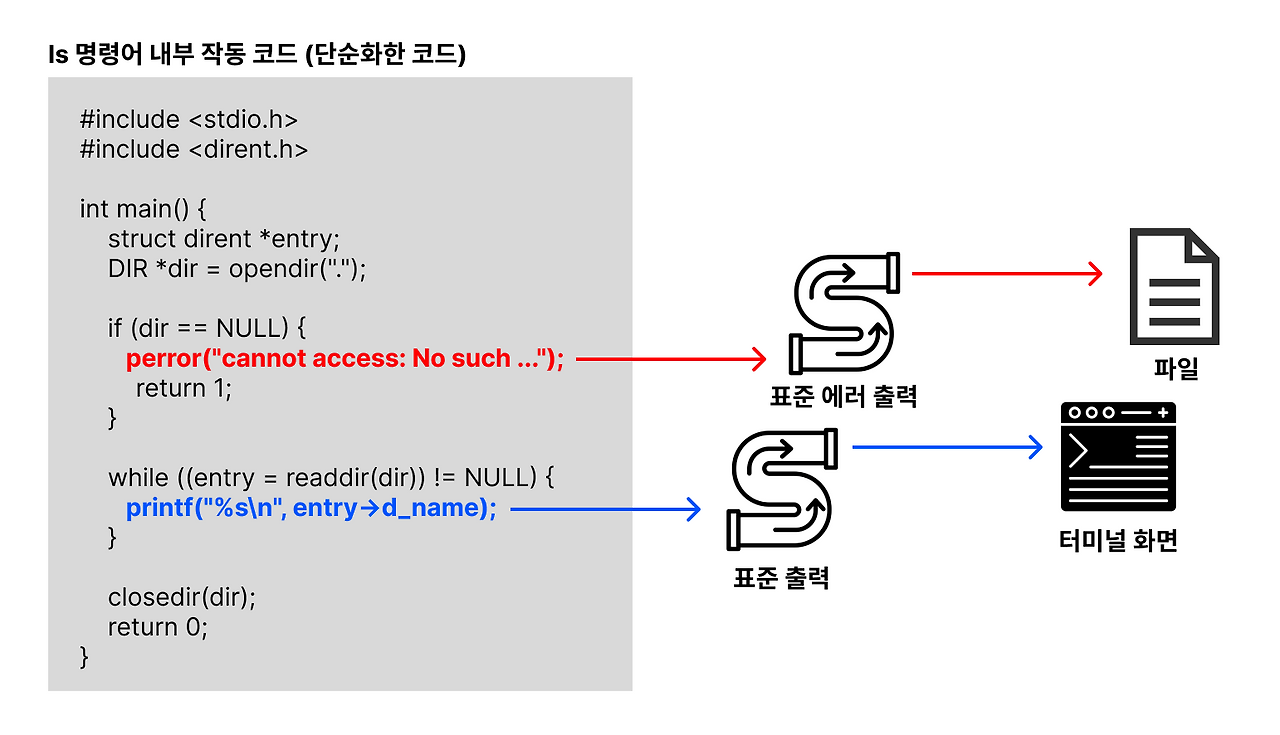
리눅스는 내부적으로 ls 명령어의 실행 결과를 터미널 화면에 출력하기 위한 함수(ex. printf() ) 를 호출했을 것이다. 체감상으로는 위의 그림과 같이 printf() 함수가 터미널 화면에 바로 출력하게끔 작동하는 것처럼 보인다. 하지만 실제로는 그렇게 작동하지 않는다.
printf() 의 정확한 역할은 터미널 화면에 결과값을 출력하는 역할이 아니라, 표준 출력 이라는 곳으로 결과값을 전달하는 역할을 한다.
그럼 여기서 얘기하는 표준 출력이 도대체 뭘까?
표준 출력(stdout) 이란, 명령어의 실행 결과를 '출력할 곳'으로 이동시켜주는 통로이다.
표준 출력에 기본값으로 설정되어 있는 출력할 곳은 '터미널 화면' 이다.
표준 출력의 출력할 곳을 '터미널 화면'이 아닌 다른 곳(ex. 파일) 으로도 바꿀 수 있다.
표준 출력(stdout) 활용해보기
터미널 창에 결과값 출력하기
표준 출력(stdout)이란, 명령어의 실행 결과를 '출력할 곳'으로 이동시켜주는 통로라고 설명했다.
아래 명령어를 입력했을 때 터미널 화면에 결과값이 출력되는 이유는, 위의 그림과 같이 표준 출력이 결과값을 기본적으로 터미널 화면에 출력하게끔 설정되어 있기 때문이다.
$ ls
$ pwd
파일에 결과값 출력하기
표준 출력의 출력할 곳을 터미널 화면이 아닌 파일로 바꿔보자.
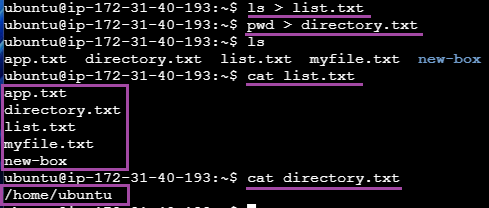
$ ls > list.txt # 터미널 화면에 아무것도 출력이 안됨
$ pwd > directory.txt # 터미널 화면에 아무것도 출력이 안됨
# 파일에 결과값이 출력(저장)됐는지 확인하기
$ ls
$ cat list.txt
$ cat directory.txt
터미널 화면에 출력돼야 할 결과값이 파일에 출력(저장)되었음을 알 수 있다.
이와 같이 표준 출력을 어디로 연결할 지 변경하는 것을 보고 리다이렉션(Redirection) 이라고 한다.
표준 에러 출력(stderr) 이란?
표준 에러 출력(stderr) 이란?
ls abc 와 같이 파라미터를 잘못 입력해 명령어를 입력하면, 명령어의 결과값이 아래와 같이 터미널 화면에 출력된다.
ls abc 명령어의 결과값이 터미널 화면에 출력되는 방식이 아닌, 파일에 출력되는 방식으로 작동시키기 위해 아래와 같이 명령어를 실행시켜봤다.
$ ls abc > list2.txt
# ls abc 명령어의 결과값이 파일에 잘 출력되었는지 확인하기
$ ls
$ cat list2.txt
그런데 여전히 cannot access 'abc': No such file or directory 라는 메시지가 출력었다. 그리고 list2.txt 파일이 생성되었지만 안에는 아무 내용도 저장되지 않았다. 왜 그럴까?
리눅스에서 명령어의 실행 결과가 아닌 에러 메시지를 출력할 때는 별도의 메서드를 호출(ex. perror() ) 해서 출력한다. 즉, 정상적인 실행 결과값을 출력하는 함수와 에러 메시지를 출력하는 함수가 구별되어 있다. 이 때, 에러 메시지를 출력하는 함수인 perror() 의 역할은 표준 에러 출력 이라는 곳으로 에러 메시지를 전달하는 역할을 한다. 그러면 에러 메시지를 전달 받은 표준 에러 출력은, 기본적으로 터미널 화면에 에러 메시지를 출력한다.
위 예제에서는 ls abc > list2.txt 라는 명령어를 통해 표준 출력을 터미널 화면이 아닌 파일로 연결되도록 바꿨다. 하지만 표준 출력과 표준 에러 출력은 서로 독립적인 통로이기 때문에, 에러 메시지가 발생했을 때는 표준 출력이 아닌 표준 에러 출력의 통로를 거쳐 터미널 화면으로 에러 메시지가 출력된 것이다.
그럼 어떻게 해야 에러 메시지를 터미널 화면이 아닌 파일로 출력되게 만들 수 있을까?
아래 명령어와 같이 > 가 아닌 2> 라는 기호를 사용해야 한다. 그러면 표준 에러 출력은 파일에 저장된다. 확인해 보자.
$ ls abc 2> list3.txt
# 표준 에러 출력이 파일에 잘 저장되었는지 확인
$ ls
$ cat list3.txt
에러 메시지가 터미널 화면에 출력되지 않고 파일에 저장되는 것을 확인할 수 있다. 아래의 그림과 같이 작동한 것이다.
한 가지 더 테스트 해보자.
아래와 같이 명령어를 입력했을 때 명령어의 정상적인 결과값은 어떻게 처리가 되는 지 확인해보자.
$ ls 2> list4.txt
# 표준 출력이 파일에 저장되는 지 확인
$ ls
$ cat list4.txt
에러 메시지가 아닌 정상적인 결과값은 표준 출력을 통해 전달되므로 파일이 아닌 터미널 화면으로 출력되는 것을 확인 할 수 있다.
표준 출력과 표준 에러 출력 둘 다 파일로 출력(= 리다이렉션) 하고 싶다면 어떻게 해야 할까?
'표준 출력' 과 '표준 에러 출력' 둘 다 파일로 출력하려면?
1. 서로 다른 파일로 출력하게 만들고 싶은 경우
$ ls > list.txt 2> error.txt # 정상적인 결과값을 출력하는 경우
$ ls xxx > list.txt 2> error.txt # 에러 메시지를 출력하는 경우
2. 같은 파일로 출력하게 만들고 싶은 경우
$ ls > all.txt 2> all.txt # 이렇게 작성하면 충돌로 인해 메시지가 잘못 기록될 수 있다.
$ ls > all.txt 2> &1 # 이렇게 작성하는 것이 올바른 방식이다.
정리
표준 출력(stdout) 이란, 명령어의 실행 결과를 '출력할 곳'으로 이동시켜주는 통로이다.
표준 출력을 어디로 연결할 지 변경할 때(= 리다이렉션)는 > 를 사용한다.
표준 에러 출력(stderr) 이란, 명령어를 실행 시 발생한 에러 메시지를 '출력할 곳'으로 이동시켜주는 통로이다.
표준 에러 출력을 어디로 연결할 지 변경할 때 (= 리다이렉션) 는 2> 를 사용한다.
표준 출력(stdout)과 표준 에러 출력(stderr) 의 추가 기능
기존 파일에 덮어 쓰기 vs 기존 파일에 이어서 쓰기
1. 표준 출력인 경우
[기존 파일에 덮어 쓰기]
$ pwd > result.txt # pwd 의 출력 결과값을 result.txt 파일에 저장
# 파일에 출력값이 잘 저장되었는지 확인
$ ls
$ cat result.txt
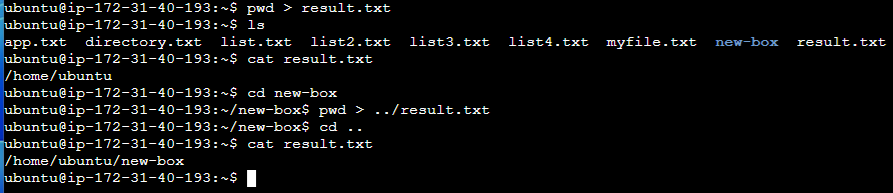
# 경로 이동 후 pwd 의 출력 결과값을 이전 경로의 result.txt 파일에 저장
# 한 번 더 이 명령어를 실행시키면 기존파일에 덮어씌움 (즉, 기존 파일의 내용이 날아감)
$ cd nex-box
$ pwd > ../result.txt
일반적으로 서버를 운영하다보면 로그를 꾸준히 쌓아나가는 게 중요하다. 그런데 명령어 새로 한번 쳤다고 기존 파일의 내용이 덮어씌워지면 문제가 될 수 있다. 따라서 기존 파일의 내용은 사라지지 않은 채로 기존 파일에 출력값을 이어서 작성하는 방법을 알아보자.
[기존 파일에 이어서 쓰기]
# 기존 파일 내용 확인
$ cat result.txt
# 기존 파일에 이어서 출력값 남기기
$ pwd >> result.txt
# 파일 내용 확인
$ cat result.txt
1. 표준 에러 출력인 경우
[기존 파일에 덮어 쓰기]
$ ls abc 2> error.txt # ls 의 에러 출력 결과값을 error.txt 파일에 저장
# 파일에 출력값이 잘 저장되었는지 확인
$ ls
$ cat error.txt
# 한 번 더 이 명령어를 실행시키면 기존 파일을 덮어 씌움
$ ls abc 2> error.txt
[기존 파일에 이어서 쓰기]
# 기존 파일 내용 확인
$ cat error.txt
# 기존 파일에 이어서 출력값 남기기
$ ls abc 2>> error.txt
# 파일 내용 확인
$ cat error.txt
# 한 번 더 테스트해보기
$ ls fff 2>> error.txt
$ cat error.txt
정리
> 대신 >> 를 사용하면 파일을 덮어쓰지 않고 파일의 끝에 이어서 출력값을 덧붙여 기록하게 된다. 만약 기존의 출력값이 사라지면 안 되는 경우에는 반드시 >> 를 사용하도록 하자.
Spring Boot 서버가 출력하는 로그를 파일로 남기기
사전 환경 세팅
1. JDK 설치하기
Java 17을 기준으로 구성되 Spring Boot 서버를 실행시킬 예정이다. Spring Boot 서버를 실행시키려면 JDK 가 설치되어 있어야 한다. 따라서 JDK 17버전을 설치해보자.
$ sudo apt update # 패키지 목록 최신화
$ sudo apt install openjdk-17-jdk # openjdk-17-jdk라는 패키지 설치
2. 잘 설치됐는지 확인하기
$ sudo apt list --installed | grep openjdk-17-jdk # 설치된 패키지 확인하기
$ java -version # 설치된 자바 버전 확인하기
$ sudo apt list --installed ❘ grep openjdk-17-jdk
$ java -version
3. 서버 실행시키기
# 기존 빌드된 파일을 삭제하고 새롭게 JAR 로 빌드
$ ./gradlew clean build
# 새롭게 빌드된 JAR 파일은 build/libs 에 있다
$ cd build/libs
# 지정한 JAR 파일을 하나의 독립 실행 프로그램처럼 JVM 위에서 실행
$ java -jar linux-springboot-0.0.1-SNAPSHOT.jar
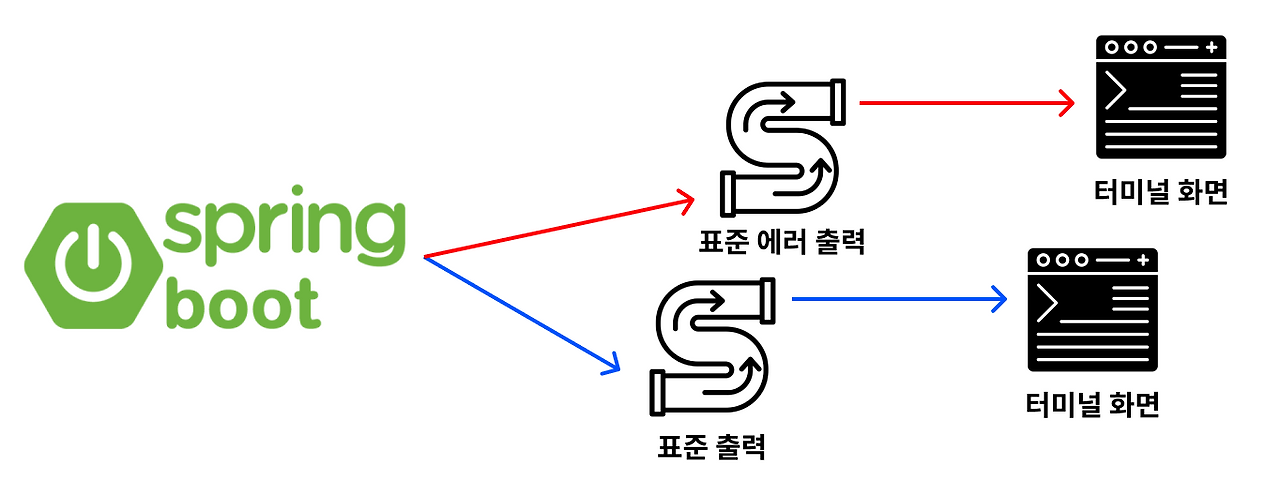
Spring Boot 프로젝트를 실행시켰더니 로그가 터미널 화면에 출력된 것을 확인할 수 있다. 즉, 아래와 같이 구성되어 있을 것이다.
그렇다면 이 구조에서 Spring Boot의 로그를 터미널 화면이 아닌 파일에 남기게끔 바꿔보자.
Spring Boot 서버가 출력하는 로그를 파일로 남기기
1. 실행시킨 서버 종료시키기
Ctrl + c 누르기
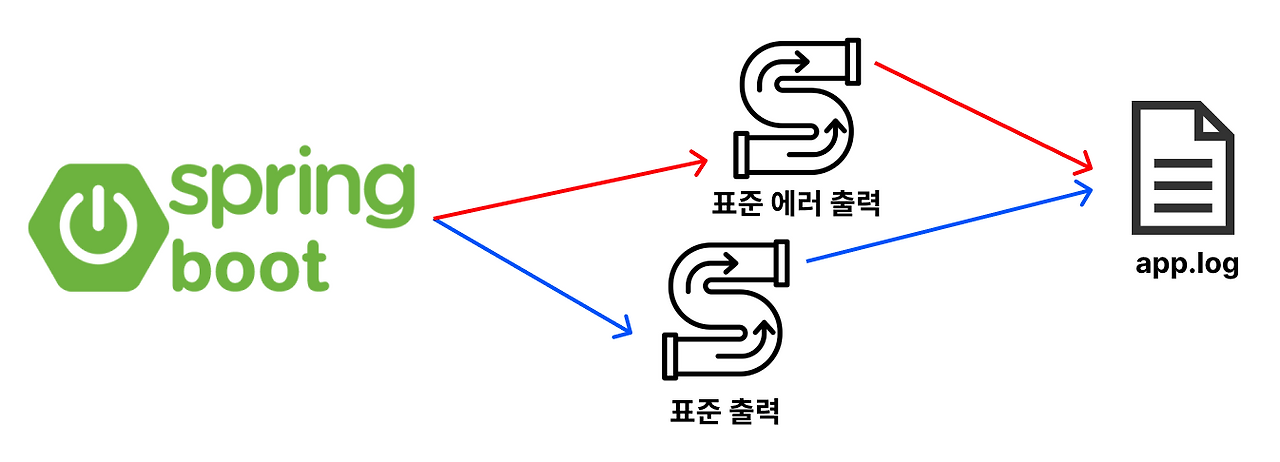
2. 표준 출력과 표준 에러 출력을 파일로 리다이렉션하기
# 표준 출력과 표준 에러 출력에서 발생하는 값을 app.log 파일로 전송
$ java -jar linux-springboot-0.0.1-SNAPSHOT.jar >> app.log 2>&1
표준 출력과 표준 에러 출력을 같은 파일로 출력하게 만들기 위해 2>&1 을 사용
Spring Boot 를 실행시킬 때마다 기존 로그 파일의 내용이 삭제되지 않게 > 대신에 >> 를 사용
3. 로그가 파일에 잘 저장되었는지 확인하기
# Ctrl + c 로 서버 종료 후 app.log 파일 출력하기
$ ls
$ cat app.log
갤럭시(Android)에서 앱을 받을 때는 Play Store 를 활용하고, 아이폰(iOS)에서 앱을 받을 때는 App Store를 활용할 것이다. 이처럼 개발 환경에서는 프로그램(소프트웨어, 라이브러리 등)을 설치할 때 패키지 매니저를 사용한다. 패키지 매니저는 운영체제 또는 개발환경에 따라 그에 맞는 패키지 매니저를 사용해야 한다.
node 환경 → npm , yarn
spring 환경 → gradle , maven
python 환경 → pip
리눅스 환경 → apt , yum , dnf 등
Ubuntu 에서는 apt 를 사용한다.
CentOS에서 yum 또는 dnf 를 사용한다.
패키지 매니저는 프로그램을 설치할 때 뿐만 아니라, 업데이트 및 제거를 할 때도 사용한다. 따라서 패키지 매니저는 프로그램을 설치, 업데이트, 제거를 쉽게 관리해주는 도구라고 할 수 있다.
자주 사용하는 apt 명령어 4가지
1. 패키지 설치
$ sudo apt install [패키지명]
apt 를 활용해 패키지를 설치하는 명령어를 입력하는 순간, apt 패키지 저장소로부터 해당 패키지를 다운 받아온다. 예를 들어, Ubuntu 컴퓨터에서 sudo apt install nginx 라고 명령어를 입력하는 순간 apt 패키지 저장소로부터 nginx 프로그램을 다운받아와 설치한다.
2. 패키지 목록 최신화
$ sudo apt update
여기서 '패키지 목록 최신화' 가 무슨 말인지 먼저 이해해보자.
Ubuntu 컴퓨터에서는 내부적으로 apt 패키지 저장소로부터 어떤 소프트웨어를 설치할 수 있는지에 대한 아래와 같은 패키지 목록을 가지고 있다. (아래는 단순 예시일 뿐이다.)
mysql 7.68.0
nginx 2.15.2
curl 8.5.0
git 2.39.2
vim 9.0.1677
openssh-server 1:9.0p1-1
python3 3.10.12-1
gcc 12.3.0.-1
make 4.3-4.1build1
docker.io 24.0.5-0ubuntu1~22.04.1
postgresql 14.10-0ubuntu0.22.04.1
...
apt 패키지 저장소에는 소프트웨어 개발자들에 의해 하루에도 수백개의 패키지가 새로 업데이트 되고 있다. 그런데 Ubuntu 컴퓨터가 가지고 있는 apt 패키지 목록은 apt 패키지 저장소와 실시간으로 동기화되면서 업데이트 되지 않는다. 그래서 apt 패키지 저장소에 있는 소프트웨어 목록을 수동으로 동기화해주어야 한다.
여기서 수동으로 동기화하는 작업을 보고 '패키지 목록 최신화' 라고 말한다.
패키지 목록 최신화 작업은 주로 특정 패키지를 설치하기 전에 수행한다. 그래야 최신화된 소프트웨어 목록을 기반으로 소프트웨어를 설치할 수 있기 때문이다.
3. 설치된 패키지 확인하기
apt를 활용해 패키지를 설치한 이후에 정말 잘 설치되었는 지 확인하고 싶을 수 있다. 이때, 아래 명령어를 활용한다.
# 현재 컴퓨터에 설치된 모든 패키지 목록을 출력
$ sudo apt list --installed
# 설치된 특정 패키지 확인
$ sudo apt list --installed | grep [패키지명]
4. 패키지 삭제
# 설치된 패키지에 관련된 모든 파일을 깔끔하게 삭제
$ sudo apt purge --auto-remove [패키지명]
패키지를 삭제하는 명령어는 apt purge 명령어 말고 apt remove 라는 명령어도 있다. apt remove 명령어는 설정 파일을 남겨둔 채로 패키지를 삭제하기 때문에 깔끔하게 삭제되지 않고 찌꺼기 파일이 남게 된다. 따라서 패키지를 완전히 깔끔하게 삭제하고 싶을 때는 apt purge 명령어를 주로 사용한다.
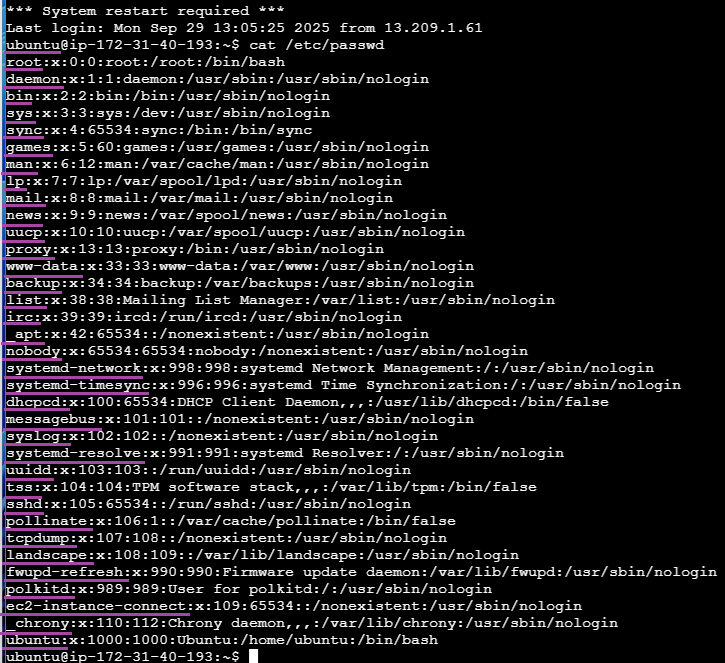
다음은 리눅스 환경에서 기본적으로 생성되어 있는 사용자들이다. 첫 번째 : 을 기준으로 왼쪽에 있는 값들이 사용자들(users)이다. 기본적으로 root , daemon, bin, sys 등 다양한 사용자가 이미 생성되어 있다. 여러 사용자들 중에서 가장 위에 있는 root 와 가장 아래에 있는 ubuntu 만 거의 사용하니 이 두 가지 사용자만 기억해두자.
리눅스 사용자
리눅스에서 사용자 유형
슈퍼 사용자 (관리자) : 시스템의 모든 권한을 가진 계정
어떠한 제한도 없이 모든 명령어를 실행시킬 수 있으며 모든 파일을 조작할 수 있다.
실수로 중요한 시스템 파일을 지우는 것도 가능하므로, 안전을 위해 평소에는 일반 사용자 계정을 사용하는 것을 추천한다.
일반적으로 root 계정이 슈퍼 사용자로 설정되어 있다.
일반 사용자
권한이 허용된 명령어만 실행시킬 수 있고, 권한이 허용된 파일만 조작할 수 있다.
실수로 중요한 시스템 파일을 지우는 것이 불가능하다.
ex) ubuntu
시스템 사용자
사람이 직접 로그인해서 쓰는 계정이 아닌, 운영체제나 서비스(데몬, 서비스 프로그램)가 동작하기 위해 만들어진 계정이다.
보안 강화 : 보안 취약점이 뚫렸을 때, root 권한이 아닌 시스템 사용자로 실행된다면 피해를 제한할 수 있다.
권한 분리 : 서비스별로 계정을 나누어 간섭을 피하고 권한을 분리한다.
관리 편의성 : 로그 파일이나 실행 파일, 설정 파일의 소유권을 해당 시스템 사용자로 두면, 관리가 깔끔해진다.
이 3가지 중 자주 사용하게 되는 슈퍼 사용자와 일반 사용자만 일단 기억하고 가자.
현재 접속한 계정은
1. 터미널 창에서 @ 왼쪽에 있는 이름이 현재 접속해있는 사용자 계정이다.
현재 접속 계정
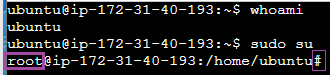
2. 명령어로 whoami 라고 입력하면 현재 접속해있는 사용자 계정을 알려준다.
현재 접속 계정 명령어 whoami
다른 사용자로 접속하려면 어떻게 할까?
슈퍼 사용자 (root 계정) 로 접속하는 방법 : $ sudo su
$sudo su
root 라는 사용자로 변경되었다.
슈퍼 사용자로 전환되면 입력창에서 $ 가 # 로 바뀐다.
# 으로 바뀌는 이유는 슈퍼 사용자임을 직관적으로 알려주기 위함이다.
일반 사용자 (ubuntu 계정) 으로 접속하는 방법 : $ su ubuntu
su ubuntu
2. 그룹(group) 이란?
그룹(group)이란?
리눅스에서 그룹(group) 이란 사용자 계정을 묶어서 관리하기 위한 단위이다. 여러 사용자에게 공통된 권한을 한번에 부여하고 관리할 때 유용하게 사용된다.
그룹(group) 의 특징
한 사용자는(user) 는 반드시 하나의 그룹(group) 에 속해야 한다.
한 사용자(user)는 여러 그룹(group) 에 속할 수 있다.
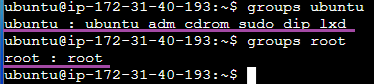
특정 계정이 어떤 그룹(group)에 속해 있는 지 확인하는 방법
group 을 확인하는 명령어 : $ groups [사용자명]
$ groups ubuntu, $ groups root
ubuntu 사용자는 ubuntu, adm, cdrom, sudo, dip, lxd 라는 그룹에 속해있다.
root 사용자는 root 라는 그룹에만 속해있다.
3. 권한(Permission) 이란?
권한(Permission)이란
리눅스에서는 여러 사용자 계정을 만들어 사용할 수 있다고 했다. 그러다보니 특정 사용자가 다른 사용자의 파일을 마음대로 접근하는 걸 막기 위해 권한(Permission) 이라는 기능을 추가했다. 권한(Permission) 을 활용하면 특정 사용자에 대해서만 특정 파일 또는 디렉터리에 접근할 수 있게 만들 수 있다.
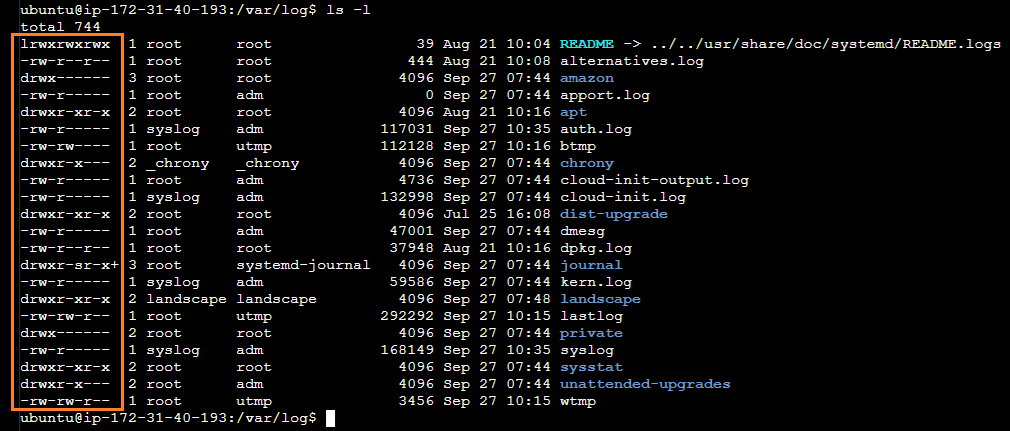
권한(Permission) 확인 방법
리눅스의 모든 파일에는 '누구에게 어떤 권한까지 허용할 지'와 '소유자'와 '소유 그룹'이 설정되어 있다. 직접 확인해 보자.
먼저 노란 박스에 표시된 계정은 소유자를 의미한다. 파일을 생성한 사용자가 자동으로 소유자가 된다. (변경 가능하다.)
그 다음 하늘색 박스에 표시된 이름은 소유 그룹을 의미한다. 파일을 생성한 사용자의 기본 그룹(primary group)으로 자동 설정 된다. (변경 가능하다.)
그 다음 보라색 박스를 보자. 보라색 박스의 문자는 아래와 같이 총 10개의 문자로 이루어져있다. 여기서 각 문자의 의미는 아래와 같다.
1. 1번째 문자 : 파일 유형(File Type)
- : 일반 파일
d : 디렉토리
l : 심볼릭 링크
2. 2~4번째 문자 : 소유자에게 허용된 권한
[일반 파일인 경우]
r (read) : 파일을 읽을 수 있다. (파일 내부 내용 확인 가능)
w (write) : 파일을 수정할 수 있다.
x (execute) : 파일을 실행할 수 있다. (실행 파일 또는 쉘 스크립트인 경우)
[디렉토리인 경우]
r : 디렉토리 내부 파일 조회 ( ls ) 가 가능하다.
w : 디렉토리 내부에 파일을 생성/삭제할 수 있다.
x : 디렉토리 내부로 접근 ( cd ) 할 수 있다.
3. 5~7번째 문자 : 소유 그룹에게 허용된 권한을 의미
4. 8~10 번째 문자 : 그 외의 사용자에게 허용된 권한을 의미
4. 권한 변경하는 방법 (chmod)
chmod 라는 명령어를 이용하면 파일에 권한을 변경할 수 있다. 숫자 3개를 활용해서 변경할 권한을 설정한다. 각 권한은 아래와 같이 해당하는 숫자에 있다. 이 숫자를 더해서 소유자, 그룹, 다른 사용자에 대한 권한을 설정할 수 있다.
예시1
어떤 파일에 소유자, 소유 그룹, 그 외의 사용자 에게 모든 권한을 부여하고 싶다고 가정하다. 그러면 아래와 같이 권한을 부여해야 한다. 어떤 계정에 모든 권한을 주고싶다면 4(r) + 2(w) +1(x) 를 더하여 7이라는 숫자를 주면 된다. 이 때, 소유자, 소유 그룹, 그 외의 사용자 에게 모든 권한을 주려면 chmod 777 하여 rwxrwxrwx 라는 권한을 부여할 수 있다.
예시2
이번에는 파일에 rw-r--r-- 라는 권한을 부여하고 싶다고 가정하자. rw- 권한은 4(r) + 2(w) +0(-) = 6 으로 주고 r-- 권한은 4(r) + 0(-) + 0(-) = 4 로 주면 된다.
그래서 chmod 644 하여 rw-r--r-- 권한을 줄 수 있다.
5. 관리자 권한 (sudo)
관리자 권한
root 사용자는 슈퍼 사용자이다. 슈퍼 사용자는 시스템의 모든 권한을 가진 계정이다. 슈퍼 사용자는 파일에 설정된 권한과 별개로 모든 권한을 가지고 있기 때문에 어떠한 조작이든 전부 다 가능하다.
root 사용자가 아니더라도 권한이 없는 파일에 접근하는 방법
일반 사용자가 슈퍼 사용자처럼 명령어를 실행하거나 파일에 접근할 수 있는 방법이 있다. 그것이 바로 sudo 라는 명령어이다.
아래에서 sudoers 라는 파일은 root계정외에는 어떠한 권한도 없다는 것을 알 수 있다.
시작 화면에서 맨 아래줄만 읽어보자. ubuntu@ip-172-31-24-185:~$ 라고 표시 되어있다. @ 앞에 있는 값이 ubuntu 는 사용자 이름이다. 윈도우 운영체제에서도 처음 시작할 때, 여러 사용자를 만들어서 사용할 수 있는것 처럼 리눅스에서도 여러 사용자를 만들어 사용할 수 있다. 그 중에서 기본 사용자의 이름을 ubuntu 로 지정해 준것이다.
@ 뒤에 있는 값인 ip-172-31-24-185 는 호스트의 이름, 즉 컴퓨터의 이름을 의미한다. 기본 값으로 우리가 대여한 해당 컴퓨터의 IP 주소로 이름이 지어진다.
~ : 현재 들어와있는 경로를 의미한다. ~ 라는 경로는 사용자의 홈 디렉토리를 의미한다.
$ : 사용자의 명령 입력을 기다린다는 표시이다.
리눅스 환경에서는 각 사용자에게 할당된 디렉토리가 있다. 그 디렉토리를 홈 디렉토리 라고 부른다.
홈 디렉토리의 경로는 /home/{사용자명} 이다. 사용자의 이름이 ubuntu 인 경우 /home/ubuntu 가 홈 디렉토리인 것이다. 이 때, 홈 디렉토리의 경로를 간결하게 표현하기 위해 ~ 로 표현한다.
기본 조작법 및 파일과 디렉토리
ctrl + 방향키
ctrl + 방향키로 space 로 띄어진 단어 단위로 커서를 이동시킬 수 있다.
ctrl + c
리눅스에서 ctrl + c 는 Esc 와 비슷한 작업 중단, 작업 취소 역할을 한다. 실행 중인 프로그램을 종료할 때도 ctrl + c 를 사용하고,
특정 작업을 중단할 때도 ctrl + c 를 이용한다.
명령어를 입력 중에 ctrl + c 를 이용해 작업을 취소하면 ^C 라는 표시가 남는다.
ctrl + c : 작업 취소
clear
clear 를 입력하면 터미널 화면을 깔끔하게 지워준다.
복사하기 / 붙여넣기
윈도우 환경에서 조작하는 터미널에서는 복사/붙여넣기가 ctrl + c, ctrl + v 로 동작하지 않는다.
복사하기 : Ctrl + Insert
붙여넣기 : Shift + Insert
우분투 리눅스의 기본 디렉토리 구조
리눅스에서 파일(file), 디렉토리(directory)의 의미
윈도우나 맥에서 얘기하는 파일(file) 과 폴더(folder)의 개념이 리눅스에서는 조금 다르다.
리눅스에서는 폴더(folder)라고 부르지 않고, 디렉토리(directory)라고 부른다. 윈도우에서의 폴더(folder)와 리눅스에서의 디렉토리directory)는 완전히 같은 개념이라고 생각해도 된다.
리눅스에서는 모든 것을 파일(file)로 간주한다. 윈도우에서는 파일(file)과 폴더(folder)가 별개의 개념이었지만, 리눅스에서는 모든 것을 파일(file)로 간주한다.
일반 파일 : 텍스트, 동영상 파일 등
디렉토리 파일 : 윈도우에서의 폴더와 같은 개념
리눅스의 기본 디렉토리 구조
우분투 리눅스 기본 디렉토리 구조
리눅스의 최상위에 있는 디렉토리( / )를 보고 루트 디렉토리라고 한다.
루트 디렉토리 안에 리눅스에 관련된 모든 파일들을 담고있다.
루트 디렉토리를 보고 최상위 디렉토리라고도 부른다.
리눅스에서 경로를 표현할 때는 슬래시 ( / )를 활용하여 경로를 간단하게 표현한다.
ex) 루트 디렉토리에 있는, var 폴더 안에 있는, log 폴더 → /var/log
리눅스에는 기본적으로 구성되어 있는 파일들이 존재한다.
/bin, /opt, /boot 등
디렉토리 조회, 이동 명령어
현재 디렉토리 경로 조회 ( pwd : print working directory )
pwd : 리눅스 환경에서 현재 내가 위치한 경로를 조회한다.
디렉토리 이동 ( cd )
cd 이동할 경로 : 지정한 경로로 경로를 이동한다.
cd .. : 현재 디렉토리 경로에서 상위 디렉토리 (..) 로 이동
현재 디렉토리 내부에 있는 파일 조회 ( ls )
ls : 현재 디렉토리 내부의 파일을 조회한다.
ls -l : 현재 디렉토리 파일 조회(ls) + 자세한 정보 조회 (-l)
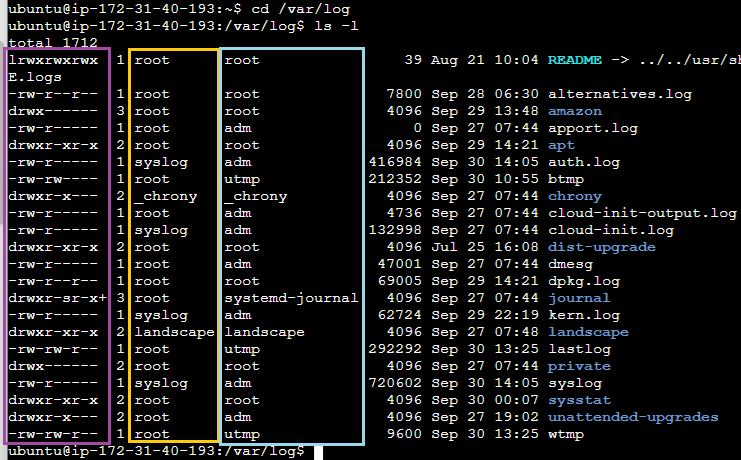
맨 왼쪽 정보에서 d 로 시작하는 파일을 디렉토리를 의미하고 - 로 시작하는 파일은 일반 파일을 의미한다.
숨김 파일 조회 (ls -a)
윈도우나 맥에서 숨김 파일이 존재하듯 리눅스에서도 숨김 파일이 존재한다.
리눅스에서는 ( . ) 으로 시작하는 파일명을 가진 파일은 자동으로 숨김 파일로 인식해 처리된다.
ls -a : 숨김 파일 조회
리눅스 명령어들의 공통적인 패턴 - 옵션(Option)
위에서 ls 라는 명령어 뒤에 -l , -a 와 같은 문자를 덧붙여 사용했다. 여기서 -l , -a 와 같이 하이픈 ( - ) 으로 시작하는 명령어를 리눅스에서는 옵션(Option) 이라고 부른다.
옵션(Option)의 특징
옵션(option)은 short option 과 long option 으로 2가지 형태를 가진다.
일반적으로 short option 은 하이픈 한 개 ( - ) 로 시작하고, long option 은 하이픈 두 개 ( -- ) 로 시작한다.
여러 옵션을 함께 사용할 수 있다.
하나의 명령어에서 여러 옵션을 함께 쓸 수 있다. ( ls -l -a )
short option 과 long option 을 같이 쓸 수 있다. ( ls -l --all )
옵션끼리는 순서가 상관없다. ( ls -a -l = ls -l -a )
short option 은 묶어서 한 번에 쓸 수 있다. ( ls -a -l = ls -al = ls -la )
모든 옵션은 명령어마다 다르다.
ls 에서 -a 옵션이 작동한다고 해서, mkdir 명령어에 -a 옵션이 동일하게 동작한다는 보장이 없다. 옵션은 명령어마다 다르게 구성되어 있다.
상대 경로, 절대 경로란?
절대 경로 : 루트 디렉토리를 기준으로 파일 위치를 표현한다.
경로가 반드시 / 로 시작한다.
상대 경로 : 현재 디렉토리를 기준으로 파일 위치를 표현한다.
경로가 / 이외의 문자로 시작한다.
. 이 현재 디렉토리 경로를 의미한다.
.. 이 상위 디렉토리 경로를 의미한다.
예시
cd /log
루트 디렉토리( / ) 에 있는 log 디렉토리로 접근
cd log
현재 디렉토리에 있는 log 디렉토리로 접근
cd ./log
현재 디렉토리 ( . ) 에 있는 log 디렉토리로 접근
cd ../log
상위 디렉토리 ( .. ) 에 있는 log 디렉토리로 접근
파일 및 디렉토리 생성 / 삭제 ( touch, mkdir, rm )
일반 파일 생성 (빈 파일 생성)
touch [파일명] : 파일명으로 빈 파일 생성
디렉토리 생성
mkdir [디렉토리명] : 디렉토리명 으로 디렉토리 생성
파일 삭제
rm [파일명] : 파일명 이름의 파일 삭제
디렉토리 삭제
rm -r [디렉토리명] : 디렉토리명 이름의 디렉토리 삭제
-r ( = --recursive ) : -r 옵션이 있어야 디렉토리를 삭제할 수 있다. 디렉토리 내부 파일까지 삭제 한다.
파일 & 디렉토리 삭제
rm -rf [파일명] : 파일이든 디렉토리든 삭제한다.
-f : 강제 삭제 (엑세스 권한이 없는 파일도 강제로 삭제하는 옵션). 편의상 이 옵션을 추가해서 삭제 명령어를 입력하는 경우가 많다.
파일 및 디렉토리 복사 / 이동 / 이름 변경 ( cp, mv )
파일 복사
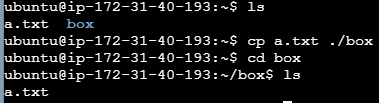
cp [복사할 파일] [복사할 위치 or 복사할 파일명]
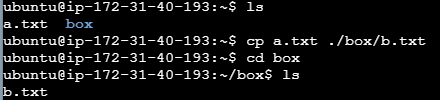
연습) 현재 디렉토리의 a.txt 파일을 ./box 경로로 복사
cp 명령어 연습
연습2) a.txt 파일을 현재 경로에 b.txt 파일로 이름을 바꿔 복사
cp 명령어 연습2
연습3) a.txt 파일을 ./box 경로에 b.txt 파일로 이름을 바꿔 복사
cp 명령어 연습3
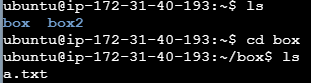
디렉토리 복사
cp -r [복사할 디렉토리] [복사할 위치 or 복사할 디렉토리명]
디렉토리를 복사할 때, -r 옵션을 넣지 않으면 에러가 발생한다.
연습4) box 디렉토리를 현재 경로에 box2 디렉토리로 이름을 바꿔 복사
cp 명령어 연습4
파일 및 디렉토리 이동
mv [이동할 파일] [이동할 위치]
연습) 현재 디렉토리에 있는 a.txt 파일을 ./box 디렉토리로 이동
mv 명령어 연습
파일 및 디렉토리 이름 변경
mv [이름 바꿀 파일] [변경할 파일명] : mv 명령어는 이름을 변경할 때도 사용된다.
연습2)box 라는 파일(디렉토리)을 new-box 라는 이름으로 변경
mv 명령어 연습2
파일 작성/조회 할 때 자주 사용하는 명령어
텍스트 에디터 ( vim )
윈도우나 맥에서 파일에 코드를 작성할 때, vscode, IntelliJ 와 같은 프로그램을 활용했을 것이다. 이런 프로그램을 보고 텍스트 에디터(Text Editor) 라고 부른다.
리눅스에서도 코드를 작성해야 하는 경우가 있는데, 리눅스 환경에서 최적화된 텍스트 에디터( vim, nano, emac 등등 ) 를 주로 사용한다. 아래에서 vim 에디터 의 기본 사용법을 알아보자.
파일 생성 ( + vim 열기 )
$ vi app.txt
app.txt 라는 파일을 생성하고 vim 에디터를 연다. app.txt 파일이 존재한다면 app.txt 를 vim 에디터로 연다.
app.txt 를 생성하고 vim 에디터를 처음 열었을 때, COMMAND 모드로 설정되어 있어 텍스트를 입력할 수 없다. INSERT 모드로 들어가야 텍스트를 입력할 수 있다.
키보드로 i 를 눌러 INSERT 모드로 전환
텍스트를 입력 후 Esc 를 누르면 다시 COMMAND 모드로 전환된다.
:wq 를 입력하면 저장 후 vim 을 종료한다.
app.txt 생성
수정한 텍스트가 없어서 vim 만 종료하고 싶다면 :q 입력하면 된다.
파일을 수정 중 저장하지 않고 종료하려면 :q! 를 입력하여 강제 종료하면 된다.
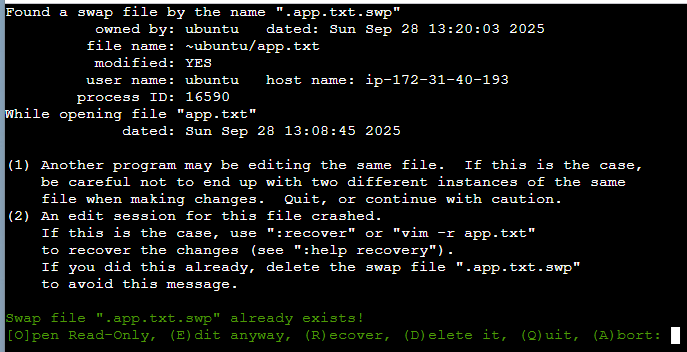
파일을 수정 중 비정상 종료 되었을 때
기존 app.txt 파일을 열어서 텍스트를 일부 수정 중 터미널 창을 새로고침하여 다시 접속 한 뒤 vim 으로 app.txt 를 열어보자.
s아래와 같은 메시지가 뜬다
수정 중 비정상 종료시 메시지
(R)ecover : r 버튼을 누르고 Enter 를 누르면 이전에 편집한 내용을 복구한 뒤, 이어서 파일을 수정할 수 있다.
(D)elete it : d 버튼을 누르면 이전에 편집한 내용을 복구하지 않고, 기존 파일에서 수정할 수 있게 된다.
(Q)uit : q 버튼을 누르면 아무 작업도 하지 않고 그냥 vim 을 종료한다.
하지만 이 메시지를 다시 띄우지 않도록 하려면 .swp 라는 확장자를 가진 파일을 지워줘야 한다. 이 파일은 vim 에서 편집 중이던 작업 내용을 임시 저장해서 비정상 종료 시 복구할 수 있도록 한다.
vim 으로 파일을 다시 수정 후 .swp 파일을 지워주도록 한다. .swp 파일은 숨김 파일이므로 ls -a 로 조회해야 한다.